Domain Memory Opcode Performance: Reading and Writing
In last week’s primer on the new domain memory (“Alchemy”) opcodes the initial test showed that they couldn’t match the performance of good old Vector when writing out a lot of float/Number values. Today’s article expands on that test to check the performance of writing integers and the performance of reading integers and float/Number values. Can the domain memory opcodes redeem themselves? Read on to find out.
As with last week’s primer, the goal of the “write” tests is to fill a Vector or contiguous block of the domain memory ByteArray with values. In today’s test that means writing int, uint, and Number values to a Vector and 8-, 16-, and 32-bit integers as well as 32- and 64-bit floating point values to the domain memory ByteArray. Here’s the source code:
package { import flash.utils.Endian; import avm2.intrinsics.memory.si32; import avm2.intrinsics.memory.si16; import avm2.intrinsics.memory.si8; import avm2.intrinsics.memory.sf64; import avm2.intrinsics.memory.sf32; import avm2.intrinsics.memory.li32; import avm2.intrinsics.memory.li16; import avm2.intrinsics.memory.li8; import avm2.intrinsics.memory.lf64; import avm2.intrinsics.memory.lf32; import flash.system.ApplicationDomain; import flash.utils.getTimer; import flash.utils.ByteArray; import flash.text.TextFieldAutoSize; import flash.display.StageScaleMode; import flash.display.StageAlign; import flash.text.TextField; import flash.display.Sprite; public class FillInts extends Sprite { private var __logger:TextField = new TextField(); private function row(...cols): void { __logger.appendText(cols.join(",")+"\n"); } public function FillInts() { stage.align = StageAlign.TOP_LEFT; stage.scaleMode = StageScaleMode.NO_SCALE; __logger.autoSize = TextFieldAutoSize.LEFT; addChild(__logger); init(); } private function init(): void { const SIZE:uint = 10000000; var i:uint; var vecInt:Vector.<int> = new Vector.<int>(SIZE); var vecUInt:Vector.<int> = new Vector.<int>(SIZE); var vecNumber:Vector.<Number> = new Vector.<Number>(SIZE); var domainMemory:ByteArray = new ByteArray(); domainMemory.length = SIZE*19; domainMemory.endian = Endian.LITTLE_ENDIAN; var int32s:uint = 0; var int16s:uint = SIZE*4; var int8s:uint = int16s + SIZE*2; var float64s:uint = int8s + SIZE; var float32s:uint = float64s + SIZE*8; var curAddr:uint; var beforeTime:int; var afterTime:int; var valInt:int; var valUInt:uint; var valNumber:Number; ApplicationDomain.currentDomain.domainMemory = domainMemory; row("Storage", "Write Time"); beforeTime = getTimer(); for (i = 0; i < SIZE; ++i) { vecInt[i] = i; } afterTime = getTimer(); row("Vector (int)", (afterTime-beforeTime)); beforeTime = getTimer(); for (i = 0; i < SIZE; ++i) { vecUInt[i] = i; } afterTime = getTimer(); row("Vector (uint)", (afterTime-beforeTime)); beforeTime = getTimer(); for (i = 0; i < SIZE; ++i) { vecNumber[i] = i; } afterTime = getTimer(); row("Vector (Number)", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = int32s; for (i = 0; i < SIZE; ++i) { si32(i, curAddr); curAddr += 4; } afterTime = getTimer(); row("Domain Memory (int32)", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = int16s; for (i = 0; i < SIZE; ++i) { si16(i, curAddr); curAddr += 2; } afterTime = getTimer(); row("Domain Memory (int16)", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = int8s; for (i = 0; i < SIZE; ++i) { si8(i, curAddr); curAddr++; } afterTime = getTimer(); row("Domain Memory (int8)", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = float64s; for (i = 0; i < SIZE; ++i) { sf64(i, curAddr); curAddr++; } afterTime = getTimer(); row("Domain Memory (float64)", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = float32s; for (i = 0; i < SIZE; ++i) { sf32(i, curAddr); curAddr++; } afterTime = getTimer(); row("Domain Memory (float32)", (afterTime-beforeTime)); row("Storage", "Read Time"); beforeTime = getTimer(); for (i = 0; i < SIZE; ++i) { valInt = vecInt[i]; } afterTime = getTimer(); row("Vector (int)", (afterTime-beforeTime)); beforeTime = getTimer(); for (i = 0; i < SIZE; ++i) { valUInt = vecUInt[i]; } afterTime = getTimer(); row("Vector (uint)", (afterTime-beforeTime)); beforeTime = getTimer(); for (i = 0; i < SIZE; ++i) { valNumber = vecNumber[i]; } afterTime = getTimer(); row("Vector (Number)", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = int32s; for (i = 0; i < SIZE; ++i) { valInt = li32(curAddr); curAddr += 4; } afterTime = getTimer(); row("Domain Memory (int32)", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = int16s; for (i = 0; i < SIZE; ++i) { valInt = li16(curAddr); curAddr += 2; } afterTime = getTimer(); row("Domain Memory (int16)", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = int8s; for (i = 0; i < SIZE; ++i) { valInt = li8(curAddr); curAddr++; } afterTime = getTimer(); row("Domain Memory (int8)", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = float64s; for (i = 0; i < SIZE; ++i) { valNumber = lf64(curAddr); curAddr++; } afterTime = getTimer(); row("Domain Memory (float64)", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = float32s; for (i = 0; i < SIZE; ++i) { valNumber = lf32(curAddr); curAddr++; } afterTime = getTimer(); row("Domain Memory (float32)", (afterTime-beforeTime)); } } }
I ran this test in the following environment:
- Release version of Flash Player 11.8.800.97
- 2.3 Ghz Intel Core i7
- Mac OS X 10.8.4
- ASC 2.0 build 353448 (
-debug=false -verbose-stacktraces=false -inline)
And here are the results I got:
| Storage | Write Time |
|---|---|
| Vector (int) | 22 |
| Vector (uint) | 22 |
| Vector (Number) | 23 |
| Domain Memory (int32) | 24 |
| Domain Memory (int16) | 25 |
| Domain Memory (int8) | 23 |
| Domain Memory (float64) | 27 |
| Domain Memory (float32) | 28 |
| Storage | Read Time |
|---|---|
| Vector (int) | 19 |
| Vector (uint) | 19 |
| Vector (Number) | 20 |
| Domain Memory (int32) | 16 |
| Domain Memory (int16) | 21 |
| Domain Memory (int8) | 17 |
| Domain Memory (float64) | 18 |
| Domain Memory (float32) | 19 |
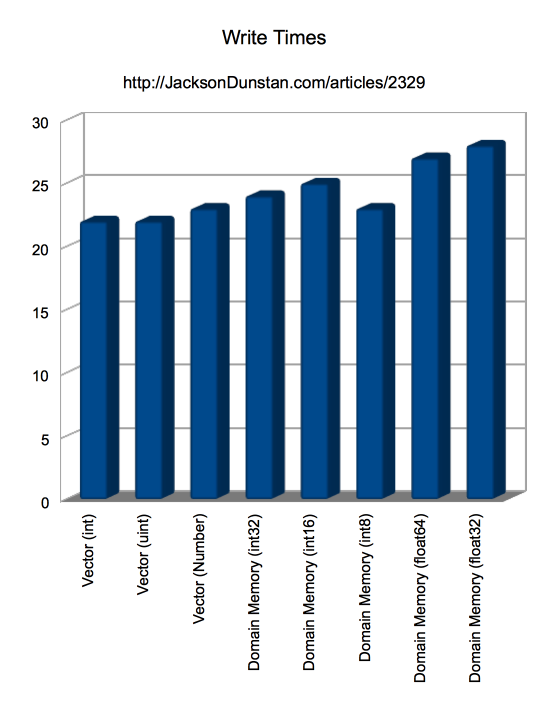
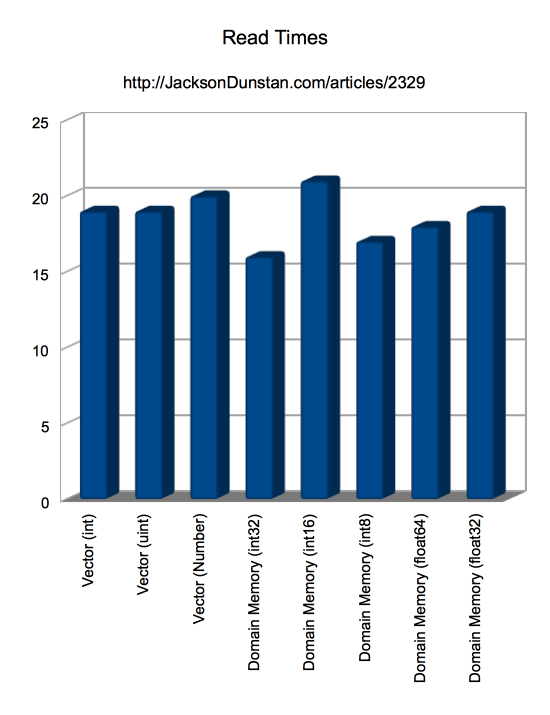
In testing integers in addition to the floats last week we see that the performance is similarly worse than that of Vector regardless of the size of the integer being stored, even down to 8-bit. With reads the there is more of a mixed bag. Reading is mostly faster with domain memory with the exception of 16-bit integers. The margins here are small, these sorts of tests are notoriously fickle, and hardware will play a big role in the results. But overall it’s at least safe to say that domain memory is competitive with Vector at these tasks. More testing will be required to see if it can really shine elsewhere.
Spot a bug? Have a question or suggestion? Post a comment!
#1 by Craig Murray on July 29th, 2013
So would you say these tests suggest that the new ASC2.0 compiler uses native memory for it’s Vectors?
#2 by jackson on July 29th, 2013
Having looked at the generated bytecode and seen no domain memory opcodes, I wouldn’t. What’s happening at the Flash Player level (including the JIT) is anybody’s guess though. Whatever it’s doing, it’s optimized enough to match or beat so-called “direct” memory access to the domain memory.
#3 by benjamin guihaire on July 30th, 2013
it would be interesting to test with various flash versions(11.4 , 11.5 11.6 etc… ), to see if adobe optimized the Vector class, or made the alchemy opcode slower, it seems to me that alchemy opcode used to be way faster than vector code before.
#4 by jackson on July 30th, 2013
I’d like to see such a comparison, too. Unfortunately, there are some issues even building the code for these old versions of Flash Player. The domain memory opcode support in ASC 2.0 requires Flash Player 11.6, so there’s no support for 11.5 and prior. If you strip out the domain memory opcodes you can’t compare directly against the old versions but you can at least compare the
Vectortests. However, ASC 2.0 won’t compile for any player before 10.1, so 10.0 would be left out. I’ve done a quick test and do see some dramatic optimization. On Windows 7 64-bit with an 2.67 GHz Intel X550 I get these results for Flash Player 10.1:11.0:
11.1:
11.2:
11.8:
So Flash Player 11.2 highly optimized
Vector, at least in this test. As you point out, this means that domain memory is doing worse in comparison. At least in Flash Player 11.6, 11.7, and 11.8 there doesn’t seem to be a difference between the domain memory speed, so it seems to be purely an optimization on the AS3 side that accounts for the shrinking difference.#5 by benjamin guihaire on July 31st, 2013
Thanks Jackson, here my own tests:
http://guihaire.com/code/?p=594
#6 by davyzhang on August 13th, 2013
Thanks jakson, you compared the bytearray with vector, but if compared to as3 native bytearray, vector is much more faster, so domain memory bytearray could be a catch up but not faster than vector.
#7 by Glidias on November 16th, 2013
Well, but domain memory with bytrArray is good to pack bytes/shorts efficiently. You can’t do that with a Vector, even with bitmasking, u r still limited to 3 bytes bytes per int due to sentinel 0x80000000 bit. In some cases, saving on mem storage is a better option.
#8 by Nicki on June 22nd, 2014
Quality articles or reviews is the important to invite the users to go to see the web page, that’s what this
website is providing.