Bytecode Analysis: Why do-while Is so Slow
The do-while loop is slower than the for and while loops… at least in Flash. Why? Today’s article digs into the bytecode the compiler generates for a variety of these loops to find out why.
Let’s jump right into the loops. First we start with a standard for loop and its bytecode. The loop body is the important part, so I’ve annotated that section.
private static function for1Loop(reps:int): int { var sum:int; for (var i:int; i < reps; ++i) { sum += i; } return sum; }
private static function for1Loop(int):int
{
// derivedName for1Loop
// method_info 3
// max_stack 2
// max_regs 4
// scope_depth 0
// max_scope 1
// code_length 28
bb0
succs=[bb2]
0 getlocal0
1 pushscope
2 pushbyte 0
3 setlocal2
4 pushbyte 0
5 setlocal3
6 jump bb2
bb1
succs=[bb2]
7 label // label to jump to when starting the loop body
8 getlocal2 // get 'sum'
9 getlocal3 // get 'i'
10 add // add 'sum' and 'i'
11 convert_i // convert result to an 'int'
12 setlocal2 // set result to 'sum'
13 inclocal_i 3 // increment 'i'
bb2
succs=[bb3,bb1]
14 getlocal3
15 getlocal1
16 iflt bb1
bb3
succs=[]
17 getlocal2
18 returnvalue
}This is a pretty literal translation of what we’ve asked for. It’s a bit ridiculous that the result of an int + int operation should need to be converted to an int, but there’s no getting around that.
Next let’s try changing the pre-increment to a post-increment as many programmers do. This will help us find out if that matters at all and perhaps settle some silly debates.
private static function for2Loop(reps:int): int { var sum:int; for (var i:int; i < reps; i++) { sum += i; } return sum; }
private static function for2Loop(int):int
{
// derivedName for2Loop
// method_info 4
// max_stack 2
// max_regs 4
// scope_depth 0
// max_scope 1
// code_length 28
bb0
succs=[bb2]
0 getlocal0
1 pushscope
2 pushbyte 0
3 setlocal2
4 pushbyte 0
5 setlocal3
6 jump bb2
bb1
succs=[bb2]
7 label
8 getlocal2
9 getlocal3
10 add
11 convert_i
12 setlocal2
13 inclocal_i 3 // same instruction
bb2
succs=[bb1,bb3]
14 getlocal3
15 getlocal1
16 iflt bb1
bb3
succs=[]
17 getlocal2
18 returnvalue
}The generated bytecode is identical because the pre- and post-increment does not matter at all. The increment expression stands on its own as an independent statement and therefore converts to the same inclocal_i instruction.
Next let’s try looping down from reps to 0:
private static function for3Loop(reps:int): int { var sum:int; for (var i:int = reps; i; --i) { sum += i; } return sum; }
private static function for3Loop(int):int
{
// derivedName for3Loop
// method_info 5
// max_stack 2
// max_regs 4
// scope_depth 0
// max_scope 1
// code_length 29
bb0
succs=[bb2]
0 getlocal0
1 pushscope
2 pushbyte 0
3 setlocal2
4 pushbyte 0
5 setlocal3
6 getlocal1
7 setlocal3
8 jump bb2
bb1
succs=[bb2]
9 label
10 getlocal2
11 getlocal3
12 add
13 convert_i
14 setlocal2
15 declocal_i 3 // decrement instead of increment
bb2
succs=[bb1,bb3]
16 getlocal3
17 iftrue bb1 // 'if (i)' instead of 'if (i < reps)'
bb3
succs=[]
18 getlocal2
19 returnvalue
}A couple of values have changed, but the loop body remains the same number of instructions. We’ll see later if the different loop iteration check matters in the performance test app results.
Now on to while. It’s normally syntactic sugar for for, but let’s make sure. First up is a while version of the first for loop:
private static function while1Loop(reps:int): int { var sum:int; var i:int; while (i < reps) { sum += i; i++; } return sum; }
private static function while1Loop(int):int
{
// derivedName while1Loop
// method_info 6
// max_stack 2
// max_regs 4
// scope_depth 0
// max_scope 1
// code_length 28
bb0
succs=[bb2]
0 getlocal0
1 pushscope
2 pushbyte 0
3 setlocal2
4 pushbyte 0
5 setlocal3
6 jump bb2
bb1
succs=[bb2]
7 label
8 getlocal2
9 getlocal3
10 add
11 convert_i
12 setlocal2
13 inclocal_i 3
bb2
succs=[bb1,bb3]
14 getlocal3
15 getlocal1
16 iflt bb1
bb3
succs=[]
17 getlocal2
18 returnvalue
}The generated bytecode is the same, proving that it is indeed syntactic sugar. Let’s try combining the sum += i and i++ expressions into a single statement. Will the compiler generate a different result?
private static function while2Loop(reps:int): int { var sum:int; var i:int; while (i < reps) { sum += i++; } return sum; }
private static function while2Loop(int):int
{
// derivedName while2Loop
// method_info 7
// max_stack 2
// max_regs 4
// scope_depth 0
// max_scope 1
// code_length 28
bb0
succs=[bb2]
0 getlocal0
1 pushscope
2 pushbyte 0
3 setlocal2
4 pushbyte 0
5 setlocal3
6 jump bb2
bb1
succs=[bb2]
7 label
8 getlocal2
9 getlocal3
10 inclocal_i 3 // increment happens earlier
11 add
12 convert_i
13 setlocal2
bb2
succs=[bb1,bb3]
14 getlocal3
15 getlocal1
16 iflt bb1
bb3
succs=[]
17 getlocal2
18 returnvalue
}The increment_i instruction occurs earlier, but the result is the same. Will the ordering matter? We’ll see in the performance test a bit later.
Now let’s try looping backwards to compare against the for version.
private static function while3Loop(reps:int): int { var sum:int; var i:int = reps; while (i) { sum += i--; } return sum; }
private static function while3Loop(int):int
{
// derivedName while3Loop
// method_info 8
// max_stack 2
// max_regs 4
// scope_depth 0
// max_scope 1
// code_length 26
bb0
succs=[bb2]
0 getlocal0
1 pushscope
2 pushbyte 0
3 setlocal2
4 getlocal1
5 setlocal3
6 jump bb2
bb1
succs=[bb2]
7 label
8 getlocal2
9 getlocal3
10 declocal_i 3 // decrement instead of increment
11 add
12 convert_i
13 setlocal2
bb2
succs=[bb3,bb1]
14 getlocal3
15 iftrue bb1 // 'if (i)' instead of 'if (i < reps)'
bb3
succs=[]
16 getlocal2
17 returnvalue
}This is the same code as the for version, but with the earlier decrement we’d expect from merging the sum += i and i-- expressions into a single statement.
Now on to do-while, the real subject of this article. Here is a descending version of the previous loop, perhaps the most common do-while loop.
private static function doWhile1Loop(reps:int): int { var sum:int; var i:int = reps; do { sum += i; } while (--i); return sum; }
private static function doWhile1Loop(int):int
{
// derivedName doWhile1Loop
// method_info 9
// max_stack 2
// max_regs 4
// scope_depth 0
// max_scope 1
// code_length 22
bb0
succs=[bb1]
0 getlocal0
1 pushscope
2 pushbyte 0
3 setlocal2
4 getlocal1
5 setlocal3
bb1
succs=[bb2,bb1]
6 label // label at start of loop body
7 getlocal2 // get 'sum'
8 getlocal3 // get 'i'
9 add // add 'sum' and 'i'
10 convert_i // convert result to an 'int'
11 setlocal2 // set result to 'sum'
12 declocal_i 3 // decrement 'i'
13 getlocal3 // get 'i'
14 iftrue bb1 // 'if (i)' go to label at start of loop body
bb2
succs=[]
15 getlocal2
16 returnvalue
}The decrement (i--) happens later in the loop, but the loop body before that is the same as with for and while. After that, however, there is no label starting a section of code that checks the loop condition. Instead, the check (if (i)) happens directly at the end of the loop body. This means that the function has only three parts—pre-loop, loop body, and post-loop—rather than four: pre-loop, loop body, loop condition check, and post-loop. Does that matter? We’ll see later.
Now for a variant where we do an ascending loop.
private static function doWhile2Loop(reps:int): int { var sum:int; var i:int = 0; do { sum += i; i++; } while (i < reps); return sum; }
private static function doWhile2Loop(int):int
{
// derivedName doWhile2Loop
// method_info 10
// max_stack 2
// max_regs 4
// scope_depth 0
// max_scope 1
// code_length 24
bb0
succs=[bb1]
0 getlocal0
1 pushscope
2 pushbyte 0
3 setlocal2
4 pushbyte 0
5 setlocal3
bb1
succs=[bb1,bb2]
6 label
7 getlocal2
8 getlocal3
9 add
10 convert_i
11 setlocal2
12 inclocal_i 3 // increment instead of decrement
13 getlocal3
14 getlocal1
15 iflt bb1 // 'if (i < reps)' instead of 'if (i)'
bb2
succs=[]
16 getlocal2
17 returnvalue
}The result here is a three-part loop as with the previous do-while function. The decrement and if (i) parts have been swapped out for for an increment and if (i < reps) as before.
Finally, here's a version with the sum += i and i++ expressions merged into a single statement.
private static function doWhile3Loop(reps:int): int { var sum:int; var i:int = 0; do { sum += i++; } while (i < reps); return sum; }
private static function doWhile3Loop(int):int
{
// derivedName doWhile3Loop
// method_info 11
// max_stack 2
// max_regs 4
// scope_depth 0
// max_scope 1
// code_length 24
bb0
succs=[bb1]
0 getlocal0
1 pushscope
2 pushbyte 0
3 setlocal2
4 pushbyte 0
5 setlocal3
bb1
succs=[bb2,bb1]
6 label
7 getlocal2
8 getlocal3
9 inclocal_i 3 // increment happens earlier, similar to 'for' and 'while'
10 add
11 convert_i
12 setlocal2
13 getlocal3
14 getlocal1
15 iflt bb1
bb2
succs=[]
16 getlocal2
17 returnvalue
}The increment happens earlier, but that's what we saw with for and while.
Next, I put all of these loops together into a simple test app:
package { import flash.display.*; import flash.utils.*; import flash.text.*; public class DoWhile extends Sprite { private var logger:TextField = new TextField(); private function row(...cols): void { logger.appendText(cols.join(",") + "\n"); } public function DoWhile() { stage.align = StageAlign.TOP_LEFT; stage.scaleMode = StageScaleMode.NO_SCALE; logger.autoSize = TextFieldAutoSize.LEFT; addChild(logger); init(); } private function init(): void { const REPS:int = 1000000000; var i:int; var beforeTime:int; var afterTime:int; var sum:int; row("Operation", "Time"); beforeTime = getTimer(); sum = for1Loop(REPS); afterTime = getTimer(); row("for1", (afterTime-beforeTime)); beforeTime = getTimer(); sum = for2Loop(REPS); afterTime = getTimer(); row("for2", (afterTime-beforeTime)); beforeTime = getTimer(); sum = for3Loop(REPS); afterTime = getTimer(); row("for3", (afterTime-beforeTime)); beforeTime = getTimer(); sum = while1Loop(REPS); afterTime = getTimer(); row("while1", (afterTime-beforeTime)); beforeTime = getTimer(); sum = while2Loop(REPS); afterTime = getTimer(); row("while2", (afterTime-beforeTime)); beforeTime = getTimer(); sum = while3Loop(REPS); afterTime = getTimer(); row("while3", (afterTime-beforeTime)); beforeTime = getTimer(); sum = doWhile1Loop(REPS); afterTime = getTimer(); row("do-while1", (afterTime-beforeTime)); beforeTime = getTimer(); sum = doWhile2Loop(REPS); afterTime = getTimer(); row("do-while2", (afterTime-beforeTime)); beforeTime = getTimer(); sum = doWhile3Loop(REPS); afterTime = getTimer(); row("do-while3", (afterTime-beforeTime)); } private static function for1Loop(reps:int): int { var sum:int; for (var i:int; i < reps; ++i) { sum += i; } return sum; } private static function for2Loop(reps:int): int { var sum:int; for (var i:int; i < reps; i++) { sum += i; } return sum; } private static function for3Loop(reps:int): int { var sum:int; for (var i:int = reps; i; --i) { sum += i; } return sum; } private static function while1Loop(reps:int): int { var sum:int; var i:int; while (i < reps) { sum += i; i++; } return sum; } private static function while2Loop(reps:int): int { var sum:int; var i:int; while (i < reps) { sum += i++; } return sum; } private static function while3Loop(reps:int): int { var sum:int; var i:int = reps; while (i) { sum += i--; } return sum; } private static function doWhile1Loop(reps:int): int { var sum:int; var i:int = reps; do { sum += i; } while (--i); return sum; } private static function doWhile2Loop(reps:int): int { var sum:int; var i:int = 0; do { sum += i; i++; } while (i < reps); return sum; } private static function doWhile3Loop(reps:int): int { var sum:int; var i:int = 0; do { sum += i++; } while (i < reps); return sum; } } }
I tested this app using the following environment:
- Release version of Flash Player 13.0.0.206
- 2.3 Ghz Intel Core i7-3615QM
- Mac OS X 10.9.2
- Google Chrome 34.0.1847.131
- ASC 2.0.0 build 354071 (
-debug=false -verbose-stacktraces=false -inline -optimize=true)
And got these results:
| Operation | Time |
|---|---|
| for1 | 2203 |
| for2 | 2178 |
| for3 | 2168 |
| while1 | 2167 |
| while2 | 2187 |
| while3 | 2169 |
| do-while1 | 2420 |
| do-while2 | 2456 |
| do-while3 | 2470 |
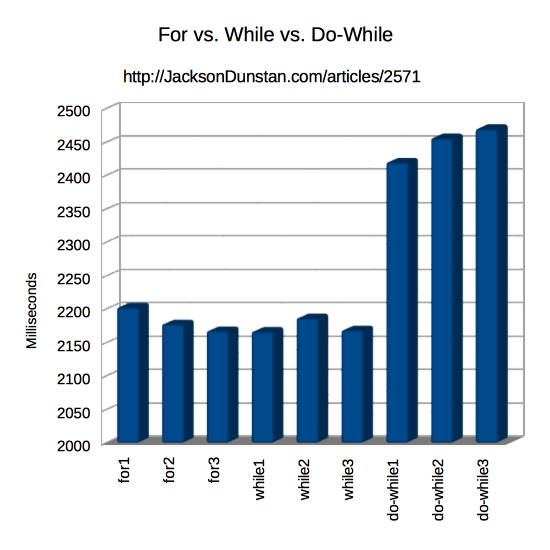
The code generated for do-while loops is really hurting its performance compared to for and while loops. The above data shows them taking about 15% longer to do the same task. Because of this severe performance penalty, there is essentially no reason to use them when one of the alternative loops will suffice.
However, none of the other variants mattered. Combining sum += i and i++ into sum += i++ didn't change the performance in any statistically-relevant way. Neither did looping in ascending order or descending order. Even though these generated pretty different bytecode, performance remained the same. As a recommendation, you should use whichever order and style makes most sense for your algorithm.
Spot a bug? Have a question or suggestion? Post a comment!
#1 by henke37 on April 28th, 2014
I blame the JIT. It is obviously designed to detect textbook for loops. Try with a little less textbook code?
#2 by jackson on April 28th, 2014
That could be it. The bytecode is similar enough that performance should be the same. A big gap must be introduced by the JIT.
#3 by Ben on April 28th, 2014
For fun I tested it with goto and it was as slow as do while. I don’t know if I used the command in a wrong way because I couldn’t find any documentation (the sum was equal to all other loops). I only remembered that it was added for FlasCC.
#4 by jackson on April 28th, 2014
I think you’ve basically created your own
do-whileloop. I haven’t disassembled it, but I’m guessing the bytecode is the same. FWIW, you could also create your ownwhileloop—or just usewhile—to boost the performance.#5 by Ben on April 29th, 2014
I also tried a while loop, but it was slower so I assumed I did something wrong. Here is the code:
private static function gotoWhileLoop(reps:int):int {
var sum:int;
var i:int;
test: if (i < reps) {
sum += i++;
goto test;
}
return sum;
}
Operation,Time
for1,1906
for2,1882
for3,1982
while1,1903
while2,1880
while3,1900
do-while1,2149
do-while2,2107
do-while3,2164
gotoDoWhile,2147
gotoWhile,2941
#6 by Nemi on April 28th, 2014
WIN 7 64bit, Chrome, 4GB
Operation,Time
for1,1945
for2,1931
for3,2191
while1,1949
while2,1920
while3,1915
do-while1,1933
do-while2,2260
do-while3,1957
#7 by jackson on April 28th, 2014
Interesting results. On my Windows PC I’m seeing similar results to the Mac results in the article. Can you tell me more about your environment, especially the CPU?
#8 by Soong on May 3rd, 2014
Operation,Time
for1,3990
for2,4124
for3,4429
while1,4080
while2,3932
while3,4496
do-while1,4082
do-while2,4028
do-while3,3665
@ WIN 7 64bit, IE11, 8GB Core i7-i3770 FP:13.0 (debug version)
#9 by jackson on May 3rd, 2014
The debug version will run slower than the release version, but in unpredictable ways. Try again with the release version to see the results as end users will.
#10 by Soong on May 4th, 2014
Operation,Time
for1,1778
for2,1778
for3,1779
while1,1738
while2,1731
while3,1732
do-while1,1950
do-while2,2028
do-while3,2246
results are simular to you.
@ WIN 7 64bit, IE11, 8GB Core i7-i3770 FP:14.0 beta
#11 by skyboy on November 13th, 2014
Curious. I can’t help but wonder what would happen with something like these:
If the first one’s label survives into the output (perhaps manually placing an unused label if not) and it is faster, then the analysis is expecting a label node in the loops when it makes whatever optimization it’s doing. Perhaps a bug report is in order?