C++ For C# Developers: Part 48 – Algorithms Library
The C++ Standard Library’s algorithms are culmination of a lot of C++ language and library features. They’re like a much more featureful, much faster version of LINQ in C#. This powerful combination makes most “raw” loops unnecessary as they can be replaced by named function calls that are well-tested and often compile to the same machine code as a “raw” loop. Read on to learn about them!
Table of Contents
- Part 1: Introduction
- Part 2: Primitive Types and Literals
- Part 3: Variables and Initialization
- Part 4: Functions
- Part 5: Build Model
- Part 6: Control Flow
- Part 7: Pointers, Arrays, and Strings
- Part 8: References
- Part 9: Enumerations
- Part 10: Struct Basics
- Part 11: Struct Functions
- Part 12: Constructors and Destructors
- Part 13: Initialization
- Part 14: Inheritance
- Part 15: Struct and Class Permissions
- Part 16: Struct and Class Wrap-up
- Part 17: Namespaces
- Part 18: Exceptions
- Part 19: Dynamic Allocation
- Part 20: Implicit Type Conversion
- Part 21: Casting and RTTI
- Part 22: Lambdas
- Part 23: Compile-Time Programming
- Part 24: Preprocessor
- Part 25: Intro to Templates
- Part 26: Template Parameters
- Part 27: Template Deduction and Specialization
- Part 28: Variadic Templates
- Part 29: Template Constraints
- Part 30: Type Aliases
- Part 31: Destructuring and Attributes
- Part 32: Thread-Local Storage and Volatile
- Part 33: Alignment, Assembly, and Language Linkage
- Part 34: Fold Expressions and Elaborated Type Specifiers
- Part 35: Modules, The New Build Model
- Part 36: Coroutines
- Part 37: Missing Language Features
- Part 38: C Standard Library
- Part 39: Language Support Library
- Part 40: Utilities Library
- Part 41: System Integration Library
- Part 42: Numbers Library
- Part 43: Threading Library
- Part 44: Strings Library
- Part 45: Array Containers Library
- Part 46: Other Containers Library
- Part 47: Containers Library Wrapup
- Part 48: Algorithms Library
- Part 49: Ranges and Parallel Algorithms
- Part 50: I/O Library
- Part 51: Missing Library Features
- Part 52: Idioms and Best Practices
- Part 53: Conclusion
Iterator
We’ve seen that containers each have an iterator class member that’s used like IEnumerator in C#: to keep track of iterating over the collection. The <iterator> header is the support library for these types. Until C++17 deprecated it, there was a std::iterator base class of all the containers’ iterator classes. This is now unnecessary with language features like concepts. Specifically, the <iterator> header provides a lot of concepts to define different kinds of iterators. Here’s how they relate to each other:
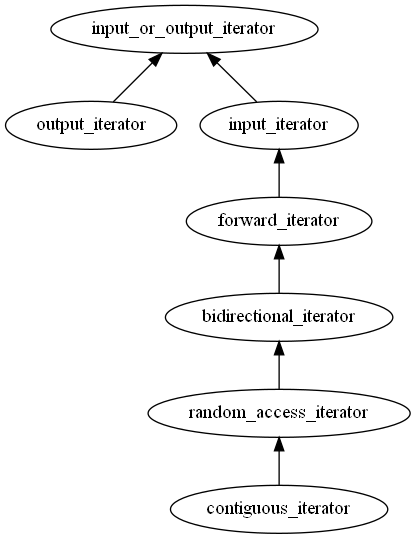
“Tag” classes are available for most of these concepts. These are empty structs that iterators and other tag classes derive from to form an inheritance hierarchy that matches the concepts:
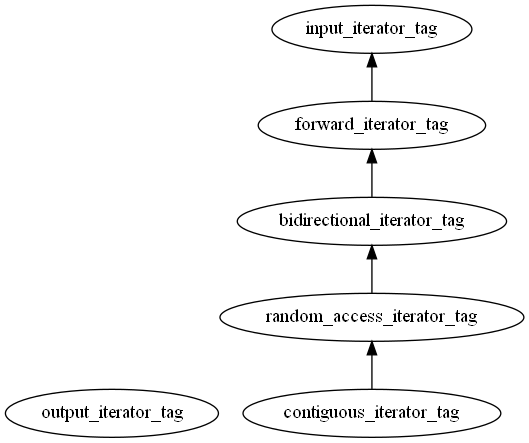
There are also concepts such as std::sortable, std::mergeable, and std::permutable that are used as requirements for various algorithms we’ll see shortly.
C# doesn’t have concepts and its IEnumerator interface doesn’t have “tag” interfaces, so there’s really no equivalent of this.
Besides concepts, <iterator> provides a lot of iterator-related utilities. This includes a lot of “adapter” classes that change the behavior of iterators. For example, std::reverse_iterator has an overloaded ++ operator that moves backward instead of forward:
#include <iterator> #include <vector> std::vector<int> v{ 1, 2, 3 }; // Adapt iterators to go backward instead of forward when using ++ std::reverse_iterator<std::vector<int>::iterator> it{ v.end() }; std::reverse_iterator<std::vector<int>::iterator> end{ v.begin() }; while (it != end) { DebugLog(*it); // 3 then 2 then 1 ++it; } // Less verbose version using class template argument deduction for (std::reverse_iterator it{ v.end() }; it != std::reverse_iterator{ v.begin() }; ++it) { DebugLog(*it); // 3 then 2 then 1 } // Even less verbose version using rebgin() and rend() for (auto it{ v.rbegin() }; it != v.rend(); ++it) { DebugLog(*it); // 3 then 2 then 1 }
There’s also a std::back_insert_iterator that overloades the assignment (=) operator to call push_back on a collection:
#include <iterator> #include <vector> // Empty collection std::vector<int> v{}; // Create an iterator to insert into the std::vector std::back_insert_iterator<std::vector<int>> it{ v }; // Insert three elements it = 1; it = 2; it = 3; for (int x : v) { DebugLog(x); // 1 then 2 then 3 }
Some functions are also available for common operations on iterators:
#include <iterator> #include <vector> std::vector<int> v{ 10, 20, 30, 40, 50 }; // Get the distance (how many iterations) between two iterators DebugLog(std::distance(v.begin(), v.end())); // 5 // Advance an iterator by a certain number of iterations std::vector<int>::iterator it{ v.begin() }; std::advance(it, 2); DebugLog(*it); // 30 // Get the next iterator DebugLog(*std::next(it)); // 40 DebugLog(*std::prev(it)); // 20
There are also some utility functions for containers:
#include <iterator> #include <vector> std::vector<int> v{ 10, 20, 30, 40, 50 }; // Check if a container is empty DebugLog(std::empty(v)); // false // Get a pointer to a container's data int* d{ std::data(v) }; DebugLog(*d); // 10
A bunch of overloaded operators are provided outside of any particular iterator class to perform binary operations on iterators:
#include <iterator> #include <vector> std::vector<int> v{ 10, 20, 30, 40, 50 }; std::vector<int>::iterator itA{ v.begin() }; std::vector<int>::iterator itB{ v.end() }; // Subtraction is a synonym for std::distance DebugLog(itB - itA); // 5 // Inequality and inequality operators compare iteration position DebugLog(itA == itB); // false DebugLog(itA < itB); // true
Some of this iterator-agnostic functionality is provided by the System.Linq.Enumerable class in C#. For example, Skip is very similar to advance in that it advances an IEnumerator forward by a given number of iterations.
Algorithm
The <algorithm> header provides a ton of functions that operate on iterators, just as LINQ in C# provides generic algorithms that operate on IEnumerable and IEnumerator. For example, std::all_of is the equivalent of Enumerable.All:
#include <algorithm> #include <vector> std::vector<int> v{ 10, 20, 30, 40, 50 }; bool allEven = std::all_of( v.begin(), // Iterator to start at v.end(), // Iterator to stop at [](int x) { return (x % 2) == 0; }); // Predicate to call with elements DebugLog(allEven); // true
Right away we see a difference from LINQ: two iterators are passed in instead of an IEnumerable with its single GetEnumerator method. This makes it easy to operate on a subset of the container such as the middle three elements of an array:
#include <algorithm> #include <vector> int v[]{ 10, 20, 30, 40, 50 }; bool allSmall = std::all_of( std::begin(v) + 1, std::begin(v) + 4, [](int x) { return x >= 20 && x <= 40; }); DebugLog(allSmall); // true
The same can be done in C#, but only by allocating new managed class objects that implement the IEnumerable interface:
using System; using System.Collections.Generic; using System.Linq; public class Program { public static void Main() { int[] a = { 10, 20, 30, 40, 50 }; // Skip allocates a class instance IEnumerable<int> skipped = a.Skip(1); // Take allocates a class instance IEnumerable<int> taken = skipped.Take(3); // Operates on only the middle three elements bool allSmall = taken.All(x => x >= 20 && x <= 40); Console.WriteLine(allSmall); // true } }
LINQ is often avoided, such as in Unity games, due to the high amount of managed allocation and eventual garbage collection involved in creating so many IEnumerable class objects. The function calls to these, and the IEnumerator objects they return, are all virtual functions which run slower than non-virtual function calls. Additional GC pressure may even be generated by “boxing” of IEnumerator structs into managed objects.
C++ algorithms, in contrast, only create lightweight iterators that aren’t garbage-collected, are never boxed, and don’t use virtual functions. The result is that compilers often totally wipe out the iterators and algorithms resulting in a “raw” loop. That “raw” loop may even be optimized away if the contents of the collection are known at compile time. For example, a command line program version of the above returns allSmall as the exit code:
#include <algorithm> #include <iterator> int main() { int v[]{ 10, 20, 30, 40, 50 }; bool allSmall = std::all_of( std::begin(v) + 1, std::begin(v) + 4, [](int x) { return x >= 20 && x <= 40; }); return allSmall; }
GCC 10.3 with basic optimization (-O1) enabled compiles this to the constant 1 (for true) on x86-64:
main: mov eax, 1 ret
As with LINQ, C++ provides dozens of algorithm functions for many common operations. Here’s a sampling of the non-modifying algorithms:
#include <algorithm> #include <vector> std::vector<int> v1{ 10, 20, 30, 40, 50 }; std::vector<int> v2{ 10, 20, 35, 45, 55 }; auto isEven = [](int x) { return (x % 2) == 0; }; // Query the contents of a vector DebugLog(std::any_of(v1.begin(), v1.begin(), isEven)); // true DebugLog(std::none_of(v1.begin(), v1.begin(), isEven)); // false // Get a pair of iterators where the vectors diverge auto mm{ std::mismatch(v1.begin(), v1.end(), v2.begin()) }; DebugLog(*mm.first, *mm.second); // 30, 35 // Get an iterator to the first matching element auto firstEven{ std::find_if(v2.begin(), v2.end(), isEven) }; DebugLog(*firstEven); // 10 // Get an iterator to the first matching element that doesn't match auto firstOdd{ std::find_if_not(v2.begin(), v2.end(), isEven) }; DebugLog(*firstOdd); // 35 // Get an iterator to the first element of an element sequence auto seq{ std::search(v1.begin(), v1.end(), v2.begin(), v2.begin() + 1) }; DebugLog(*seq); // 10
Here are some modifying algorithms:
#include <algorithm> #include <vector> #include <random> std::vector<int> v{ 10, 20, 35, 45, 55 }; auto isEven = [](int x) { return (x % 2) == 0; }; auto print = [&]() { for (int x : v) { DebugLog(x); } }; // Remove matching elements by shifting toward the front // Returns an iterator just after the new end auto end{ std::remove_if(v.begin(), v.end(), isEven) }; DebugLog(*end); // 45 print(); // 35, 45, 55 // Replace matching elements with a new value std::replace_if(v.begin(), v.end(), [](int x) { return x < 50; }, 50); print(); // 50, 50, 55, 50, 55 // Rotate left by two elements std::rotate(v.begin(), v.begin() + 2, v.end()); print(); // 55, 50, 55, 50, 50 // Randomly shuffle elements // Note: random_shuffle() isn't thread-safe and is deprecated since C++17 std::random_device rd{}; std::mt19937 gen{ rd() }; std::shuffle(v.begin(), v.end(), gen); print(); // Some permutation of 55, 50, 55, 50, 50 // Assign a value to every element std::fill(v.begin(), v.end(), 10); print(); // 10, 10, 10, 10, 10
There are also algorithms related to sorting sequences:
#include <algorithm> #include <vector> std::vector<int> v{ 35, 45, 10, 20, 55 }; auto isEven = [](int x) { return (x % 2) == 0; }; auto print = [](auto& c) { for (int x : c) { DebugLog(x); } }; // Check if a sequence is sorted DebugLog(std::is_sorted(v.begin(), v.end())); // false // Sort elements until an iterator is reached std::partial_sort(v.begin(), v.begin() + 2, v.end()); print(v); // 10, 20, 45, 35, 55 DebugLog(std::is_sorted(v.begin(), v.end())); // false // Sort the whole sequence std::sort(v.begin(), v.end()); print(v); // 10, 20, 35, 45, 55 DebugLog(std::is_sorted(v.begin(), v.end())); // true // Binary search a sorted sequence DebugLog(std::binary_search(v.begin(), v.end(), 45)); // true // Merge two sorted sequences into a sorted sequence std::vector<int> v2{ 15, 25, 40, 50 }; std::vector<int> v3{}; std::merge( v.begin(), v.end(), // First sequence v2.begin(), v2.end(), // Second sequence std::back_insert_iterator<std::vector<int>>{ v3 }); // Output iterator print(v3); // 10, 15, 20, 25, 35, 40, 45, 55 // Check if a sorted sequence includes another sorted sequence // Inclusion doesn't need to be contiguous bool inc{ std::includes(v3.begin(), v3.end(), v2.begin(), v2.end()) }; DebugLog(inc); // true
And finally there are some query operations:
#include <algorithm> #include <vector> std::vector<int> v1{ 35, 45, 10, 20, 55 }; std::vector<int> v2{ 35, 45, 10, 15, 30 }; // Check if two sequences' elements are equal DebugLog(std::equal(v1.begin(), v1.end(), v2.begin(), v2.end())); // false DebugLog( std::equal( v1.begin(), v1.begin() + 3, v2.begin(), v2.begin() + 3)); // true // Find the min, max, and both of elements in a sequence DebugLog(*std::min_element(v1.begin(), v1.end())); // 10 DebugLog(*std::max_element(v1.begin(), v1.end())); // 55 auto [minIt, maxIt] = std::minmax_element(v1.begin(), v1.end()); DebugLog(*minIt, *maxIt); // 10, 55 // Single value versions don't operate on sequences int a = 10; int b = 20; DebugLog(std::min(a, b)); // 10 DebugLog(std::max(a, b)); // 20 auto [minVal, maxVal] = std::minmax(a, b); DebugLog(minVal, maxVal); // 10, 20 // Other single value functions DebugLog(std::clamp(1000, 0, 100)); // 100 std::swap(a, b); DebugLog(a, b); // 20, 10
All of these examples have used std::vector<int>, but it’s important to know that these algorithms apply to any container type with any element type as long as the requirements of the algorithm are satisfied. This includes container and element types implemented in the C++ Standard Library as well as container and element types we create in our own code:
#include <algorithm> // A custom enum and a function to get enumerator string names enum class Element { Earth, Water, Wind, Fire }; const char* GetName(Element e) { switch (e) { case Element::Earth: return "Earth"; case Element::Water: return "Water"; case Element::Wind: return "Wind"; case Element::Fire: return "Fire"; default: return ""; } } // A custom struct struct PrimalElement { Element Element; int Power; }; // Forward-declare a class that holds an array of the custom struct class PrimalElementsArray; // An iterator type for the custom struct class PrimalElementIterator { // Keep track of the current iteration position PrimalElement* Array; int Index; public: PrimalElementIterator(PrimalElement* array, int index) : Array(array) , Index(index) { } // Advance the iterator PrimalElementIterator& operator++() { Index++; return *this; } // Compare with another iterator bool operator==(const PrimalElementIterator& other) { return Array == other.Array && Index == other.Index; } // Dereference to get the current element PrimalElement& operator*() { return Array[Index]; } }; // A class that holds an array of the custom struct class PrimalElementsArray { PrimalElement Elements[4]; public: PrimalElementsArray() { Elements[0] = PrimalElement{ Element::Earth, 50 }; Elements[1] = PrimalElement{ Element::Water, 20 }; Elements[2] = PrimalElement{ Element::Wind, 10 }; Elements[3] = PrimalElement{ Element::Fire, 75 }; } // Get an iterator to the first element PrimalElementIterator begin() { return PrimalElementIterator{ Elements, 0 }; } // Get an iterator to one past the last element PrimalElementIterator end() { return PrimalElementIterator{ Elements, 4 }; } }; // Create our custom array type PrimalElementsArray pea{}; // Use std::find_if to find the PrimalElement with more than 50 power PrimalElementIterator found{ std::find_if( pea.begin(), pea.end(), [](const PrimalElement& pe) { return pe.Power > 50; }) }; DebugLog(GetName((*found).Element), (*found).Power); // Fire, 75
Numeric
Finally for today, we’ll revisit the numbers library by looking at <numeric>. It turns out that it has some number-specific generic algorithms. Here’s a few of them:
#include <numeric> #include <vector> std::vector<int> v{}; v.resize(5); auto print = [](auto& c) { for (int x : c) DebugLog(x); }; // Initialize with sequential values starting at 10 std::iota(v.begin(), v.end(), 10); print(v); // 10, 11, 12, 13, 14 // Sum the range starting at 100 DebugLog(std::accumulate(v.begin(), v.end(), 100)); // 160 // Sum in an arbitrary order DebugLog(std::reduce(v.begin(), v.end(), 100)); // 160 // C++17: transform pairs of elements and then reduce in an arbitrary order // Equivalent to 1000000 + 10*10 + 11*10 + 12*10 + 13*10 + 14*10 DebugLog( std::transform_reduce( v.begin(), v.end(), // Sequence 1000000, // Initial value [](int a, int b) { return a + b; }, // Reduce function [](int x) { return x*10; }) // Transform function ); // 1000600 // Output sums up to current iteration std::vector<int> sums{}; std::partial_sum( v.begin(), v.begin() + 3, // Sequence std::back_insert_iterator{ sums }); // Output iterator print(sums); // 10, 21, 33
Conclusion
Both languages have a wide variety of generic algorithms but they differ quite a bit in implementation. That ranges from the trivial naming differences of enumerators and iterators to the giant performance gulf between LINQ and C++ algorithm functions in <algorithm> and <numeric>.
It’s hard to overstate just how many generic algorithms are available in the C++ Standard Library. This is especially true when looking at the huge number of permutations of each of these functions. It’s common to see five or even ten overloads of these to customize for a wide variety of parameters running the gamut from simple versions to extremely generic and flexible versions. That’s another difference with C# where LINQ functions typically have just one or two overloads.
The design of the language, especially the very powerful support for compile-time generic programming via templates, combines with the iterator paradigm to enable all of this functionality on all of the many container types but also all of the container types we might implement in our own code to suit our own needs. We inherit the same high level of optimization that C++ Standard Library types receive, which gives us little excuse for writing a lot of “raw” loops.