Free Performance with Burst
Unity 2019.1 was released last week and the Burst compiler is now out of Preview. It promises superior performance by generating more optimal code than with IL2CPP. Let’s try it out and see if the performance lives up to the hype!
To use the Burst compiler, we need to do three main things. First, we must restrict our usage of C# to the “High-Performance C#” subset. This means we don’t use any managed objects such as classes and strings. Second, we must put all our code in a C# job such as one implementing IJob or IJobParallelFor. Third, we must add the [BurstCompile] attribute to the job. If we already did the first two steps, adding the [BurstCompile] attribute is trivial enough to be considered “free” in terms of cost to implement.
So let’s write a simple job and test its performance with and without the [BurstCompile] attribute. All this job does is perform a dot product on two arrays of vectors. We’ll use the NativeArray<T> type to hold the array and the float4 type from the newly-released Unity.Mathematics package to hold the vectors. Burst is aware of the float4 type and can generate more optimal code when we use it. Here’s the test:
using System.Diagnostics; using Unity.Burst; using Unity.Collections; using Unity.Jobs; using Unity.Mathematics; using UnityEngine; class TestScript : MonoBehaviour { struct RegularJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } [BurstCompile] struct BurstJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } void Start() { const int size = 1000000; NativeArray<float4> a = new NativeArray<float4>(size, Allocator.TempJob); NativeArray<float4> b = new NativeArray<float4>(size, Allocator.TempJob); NativeArray<float4> c = new NativeArray<float4>(size, Allocator.TempJob); for (int i = 0; i < size; ++i) { a[i] = new float4(1, 1, 1, 1); b[i] = new float4(2, 2, 2, 2); } RegularJob regularJob = new RegularJob { A = a, B = b, C = c }; BurstJob burstJob = new BurstJob { A = a, B = b, C = c }; // First run is a warm-up. Second run generates the report. long regularTime = 0; long burstTime = 0; Stopwatch sw = new Stopwatch(); for (int i = 0; i < 2; ++i) { sw.Restart(); regularJob.Schedule().Complete(); regularTime = sw.ElapsedTicks; sw.Restart(); burstJob.Schedule().Complete(); burstTime = sw.ElapsedTicks; } print( "Job,Time\n" + "Regular," + regularTime + "\n" + "Burst," + burstTime); a.Dispose(); b.Dispose(); c.Dispose(); } }
Now let’s run this code to see how each job compiler performed. I ran using this environment:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.14.4
- Unity 2019.1.0f2
- macOS Standalone
- .NET 4.x scripting runtime version and API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
Here are the results I got:
| Job | Time |
|---|---|
| Regular | 43940 |
| Burst | 28590 |
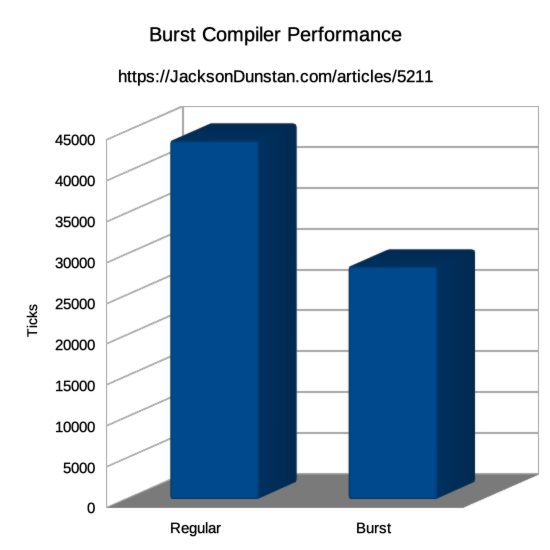
By just adding the [BurstCompile] attribute, we’ve got a major speedup! The Burst-compiled code takes 35% less time to run than the IL2CPP-compiled code. To find out why, let’s use the Burst Inspector to see the code it generated:
Jobs > Burst > Open Inspector...- Click
TestScript.BurstJobon the left - Check
Enhanced Disassemblyon the right - Uncheck
Safety Checkson the right - Click
Refresh Disassemblyon the right
Here is the section for C[i] = math.dot(A[i], B[i]):
movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] mulps xmm1, xmm0 movshdup xmm0, xmm1 addps xmm1, xmm0 movhlps xmm0, xmm1 addps xmm0, xmm1 shufps xmm0, xmm0, 0 movups xmmword ptr [rsi + rdi], xmm0
These are SIMD instructions, which tell the CPU to do the same operation on many variables at once. In this case, all four components of the float4 are operated on simulateneously to add them, multiply them, etc.
While Burst requires a change in programming style, primarily to not use classes, it provides a major performance benefit to code that complies. If the code was already written in that style, Burst offers "free" performance by simply adding the [BurstCompile] attribute to job types!
#1 by MechEthan on April 22nd, 2019 ·
Would you mind explaining, in brief, how the warmup works?
I assume, just based on the term, that it results in more consistent benchmark results, but I don’t understand why.
#2 by jackson on April 22nd, 2019 ·
That’s right. The purpose is to avoid counting any work that’s only done on the first usage. In this case the job system and Burst may do some work the first time they execute a job. The test throws away the measurements for the first job execution and only reports the measurements from the second time the job is run.
#3 by lazalong on October 22nd, 2019 ·
Knowing the timing without the warm-up is good in case we can put this phase in an initialisation. But how costly is it if we can’t do this and have the warm-up phase ‘each time’ ?
Shouldn’t we have measures with and without warm-up cost for a true comparison?
#4 by jackson on October 24th, 2019 ·
I don’t expect that many games will care about the warmup cost since it only occurs on the first run and is relatively small, but if you want to measure it just replace
i < 2withi < 1in the test and run it on your target hardware.#5 by X on April 22nd, 2019 ·
Does the Burst dependency come from UPM? Can it be used by code built into a managed .NET DLL?
#6 by jackson on April 22nd, 2019 ·
Yes, Burst 1.0.0 is now available in the Unity Package Manager. It supports code in a .NET DLL just like code directly in the project because it operates on IL, not C# source code.
#7 by X on April 23rd, 2019 ·
Given that it works on IL, it does seem possible to use the Burst-related attributes and classes in a .NET library project, but the part that I don’t see a solution for is how a VS project can depend on Burst since it’s a dependency from UPM rather than types coming from UnityEngine.dll…
I suppose this is a general problem with UPM dependencies, but as someone who builds their code into a reusable DLL rather than dropping it all into Unity, it would be awesome to have a clean way to use these Burst types in a managed assembly.
#8 by jackson on April 24th, 2019 ·
The Burst package includes an Assembly Definition file so it’s compiled into its own DLL. You can find it here:
You just need to reference that in your DLL project and you should be good to go.
#9 by Jesse TG on May 8th, 2019 ·
Thanks for the article (and for your others). Does Burst support jobs of type `IJobParallelFor`?
#10 by jackson on May 8th, 2019 ·
Yes.
#11 by Jesse TG on May 9th, 2019 ·
Sweet, thank you.
#12 by Jesse TG on May 9th, 2019 ·
New question. Inside a `IJobParallelFor` job, each iteration (or at least each thread) needs a data structure to keep track of intermediate results. What would you suggest?
#13 by jackson on May 9th, 2019 ·
That entirely depends on the data you’re looking to store and use.
NativeArray<T>is the most common type, but there are many more in the Unity.Collections package as well as my own NativeCollections repo.#14 by Jesse TG on May 14th, 2019 ·
I wound up just using a local stackalloc array of bools, but thank you.