Use the Right Type for the CPU
The Unity.Mathematics package documentation has a curious statement: “Note that currently, for an optimal usage of this library, it is recommended to use SIMD 4 wide types (float4, int4, bool4…)” Today we’ll explore why we should consider using float4, not float3, after years of using Vector3.
Let’s try using both float3 and float4 with a couple of common operations: addition and dot product. Both of these will be performed inside Burst-compiled jobs by looping over two input arrays and storing the output in a third array.
using System; using System.Diagnostics; using Unity.Burst; using Unity.Collections; using Unity.Jobs; using Unity.Mathematics; using UnityEngine; class TestScript : MonoBehaviour { [BurstCompile] struct Add3Job : IJob { public NativeArray<float3> A; public NativeArray<float3> B; public NativeArray<float3> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile] struct Add4Job : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile] struct Dot3Job : IJob { public NativeArray<float3> A; public NativeArray<float3> B; public NativeArray<float3> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } [BurstCompile] struct Dot4Job : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } void Start() { const int size = 1000000; const Allocator alloc = Allocator.TempJob; NativeArray<float3> a3 = new NativeArray<float3>(size, alloc); NativeArray<float3> b3 = new NativeArray<float3>(size, alloc); NativeArray<float3> c3 = new NativeArray<float3>(size, alloc); NativeArray<float4> a4 = new NativeArray<float4>(size, alloc); NativeArray<float4> b4 = new NativeArray<float4>(size, alloc); NativeArray<float4> c4 = new NativeArray<float4>(size, alloc); for (int i = 0; i < size; ++i) { a3[i] = float3.zero; b3[i] = float3.zero; c3[i] = float3.zero; a4[i] = float4.zero; b4[i] = float4.zero; c4[i] = float4.zero; } Add3Job a3j = new Add3Job { A = a3, B = b3, C = c3 }; Add4Job a4j = new Add4Job { A = a4, B = b4, C = c4 }; Dot3Job d3j = new Dot3Job { A = a3, B = b3, C = c3 }; Dot4Job d4j = new Dot4Job { A = a4, B = b4, C = c4 }; const int reps = 100; long[] a3t = new long[reps]; long[] a4t = new long[reps]; long[] d3t = new long[reps]; long[] d4t = new long[reps]; Stopwatch sw = new Stopwatch(); for (int i = 0; i < reps; ++i) { sw.Restart(); a3j.Run(); a3t[i] = sw.ElapsedTicks; sw.Restart(); a4j.Run(); a4t[i] = sw.ElapsedTicks; sw.Restart(); d3j.Run(); d3t[i] = sw.ElapsedTicks; sw.Restart(); d4j.Run(); d4t[i] = sw.ElapsedTicks; } print( "Operation,float3 Time,float4 Timen" + "Add," + Median(a3t) + "," + Median(a4t) + "n" + "Dot," + Median(d3t) + "," + Median(d4t)); a3.Dispose(); b3.Dispose(); c3.Dispose(); a4.Dispose(); b4.Dispose(); c4.Dispose(); Application.Quit(); } static long Median(long[] values) { Array.Sort(values); return values[values.Length / 2]; } }
Now we can use the Burst Inspector to view the assembly that Burst compiles these jobs to. Here are the instructions for the body of the float3 addition job’s loop, annotated by me.
; xmm0 = A[i] movsd xmm0, qword ptr [rcx + rdi] insertps xmm0, dword ptr [rcx + rdi + 8], 32 ; xmm1 = B[i] movsd xmm1, qword ptr [rdx + rdi] insertps xmm1, dword ptr [rdx + rdi + 8], 32 ; xmm1 = xmm1 + xmm0 addps xmm1, xmm0 ; C[i].x = xmm1.x movss dword ptr [rsi + rdi], xmm1 ; C[i].y = xmm1.y extractps dword ptr [rsi + rdi + 4], xmm1, 1 ; C[i].z = xmm1.z extractps dword ptr [rsi + rdi + 8], xmm1, 2
In total, this took 8 instructions to complete. The SIMD instruction addps is the operation the loop exists to do and everything else is just to support it. On the reading side, each movsd was accompanied by an insertps to make up for the float3 not having enough values to fill the four-float xmm registers. On the writing side, individual instructions were used to copy each component of the result vector.
Now let’s see what effect using float4 has:
; xmm0 = A[i] movups xmm0, xmmword ptr [rcx + rdi] ; xmm1 = B[i] movups xmm1, xmmword ptr [rdx + rdi] ; xmm1 = xmm1 + xmm0 addps xmm1, xmm0 ; C[i] = xmm1 movups xmmword ptr [rsi + rdi], xmm1
The float4 version requires only four instructions: half! They’re really the minimum for the work being done and are visible directly in the C# line: A[i], B[i], +, and C[i] =. Since the data in a float4 matches the data in the xmm0 and xmm1 CPU registers, there’s no need for extra instructions to act as an adapter to fit a float3 into what’s essentially a float4 register.
Now let’s look at the dot product jobs and see how that compares to the addition jobs. We won’t go into the same detail as before, but the raw instruction count tells the overall story. Here’s the float3 job:
movsd xmm0, qword ptr [rcx + rdi] insertps xmm0, dword ptr [rcx + rdi + 8], 32 movsd xmm1, qword ptr [rdx + rdi] insertps xmm1, dword ptr [rdx + rdi + 8], 32 mulps xmm1, xmm0 ; Multiply movshdup xmm0, xmm1 movaps xmm2, xmm1 movhlps xmm2, xmm2 addss xmm2, xmm0 ; Add addss xmm2, xmm1 ; Add movss dword ptr [rsi + rdi], xmm2 movss dword ptr [rsi + rdi + 4], xmm2 movss dword ptr [rsi + rdi + 8], xmm2
This took 13 instructions including one multiplication and two addition instructions.
And here’s the float4 version:
movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] mulps xmm1, xmm0 ; Multiply movshdup xmm0, xmm1 addps xmm1, xmm0 movhlps xmm0, xmm1 addps xmm0, xmm1 ; Add shufps xmm0, xmm0, 0 movups xmmword ptr [rsi + rdi], xmm0
This took only 9 instructions with just one multiplication and one addition. So as with the addition jobs, we see that using the data type that matches the CPU register results in fewer instructions for the CPU to execute.
Now let’s try running these and see what kind of performance we get. I ran them using this environment:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.14.4
- Unity 2019.1.0f2
- macOS Standalone
- .NET 4.x scripting runtime version and API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
And here are the results I got:
| Operation | float3 Time | float4 Time |
|---|---|---|
| Add | 26800 | 31180 |
| Dot | 27450 | 33990 |
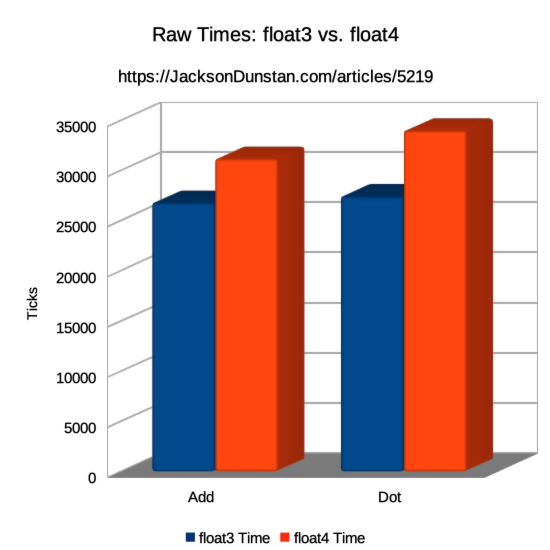
Despite all the additional instructions, the float3 version turns out to be faster than the float4 version for both addition and dot products. The reason is that the CPU instructions are not the bottleneck, but rather the speed at which memory can be read in and written out. The float3 version requires only 24 bytes where the float4 version requires 32 bytes. So with both versions the CPU is sitting idle while it waits for memory operations to complete. That “free time” means it doesn’t really matter how efficient our CPU instructions are.
However, in a real game the amount of work being done will usually be much greater than just a single addition or dot product. So let’s increase the number of operations performed on each element of the arrays from 1 to 100 and see how that affects the numbers. Here’s the updated test source code:
using System; using System.Diagnostics; using Unity.Burst; using Unity.Collections; using Unity.Jobs; using Unity.Mathematics; using UnityEngine; class TestScript : MonoBehaviour { [BurstCompile] struct Add3Job : IJob { public NativeArray<float3> A; public NativeArray<float3> B; public NativeArray<float3> C; public int NumOps; public void Execute() { for (int i = 0; i < A.Length; ++i) { float3 a = A[i]; float3 b = B[i]; float3 c = float3.zero; for (int j = 0; j < NumOps; ++j) { c += a + b; } C[i] = c; } } } [BurstCompile] struct Add4Job : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public int NumOps; public void Execute() { for (int i = 0; i < A.Length; ++i) { float4 a = A[i]; float4 b = B[i]; float4 c = float4.zero; for (int j = 0; j < NumOps; ++j) { c += a + b; } C[i] = c; } } } [BurstCompile] struct Dot3Job : IJob { public NativeArray<float3> A; public NativeArray<float3> B; public NativeArray<float3> C; public int NumOps; public void Execute() { for (int i = 0; i < A.Length; ++i) { float3 a = A[i]; float3 b = B[i]; float3 c = float3.zero; for (int j = 0; j < NumOps; ++j) { c += math.dot(a, b); } C[i] = c; } } } [BurstCompile] struct Dot4Job : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public int NumOps; public void Execute() { for (int i = 0; i < A.Length; ++i) { float4 a = A[i]; float4 b = B[i]; float4 c = float4.zero; for (int j = 0; j < NumOps; ++j) { c += math.dot(a, b); } C[i] = c; } } } void Start() { const int size = 1000000; const Allocator alloc = Allocator.TempJob; NativeArray<float3> a3 = new NativeArray<float3>(size, alloc); NativeArray<float3> b3 = new NativeArray<float3>(size, alloc); NativeArray<float3> c3 = new NativeArray<float3>(size, alloc); NativeArray<float4> a4 = new NativeArray<float4>(size, alloc); NativeArray<float4> b4 = new NativeArray<float4>(size, alloc); NativeArray<float4> c4 = new NativeArray<float4>(size, alloc); for (int i = 0; i < size; ++i) { a3[i] = float3.zero; b3[i] = float3.zero; c3[i] = float3.zero; a4[i] = float4.zero; b4[i] = float4.zero; c4[i] = float4.zero; } const int numOps = 100; Add3Job a3j = new Add3Job { A = a3, B = b3, C = c3, NumOps = numOps }; Add4Job a4j = new Add4Job { A = a4, B = b4, C = c4, NumOps = numOps }; Dot3Job d3j = new Dot3Job { A = a3, B = b3, C = c3, NumOps = numOps }; Dot4Job d4j = new Dot4Job { A = a4, B = b4, C = c4, NumOps = numOps }; const int reps = 100; long[] a3t = new long[reps]; long[] a4t = new long[reps]; long[] d3t = new long[reps]; long[] d4t = new long[reps]; Stopwatch sw = new Stopwatch(); for (int i = 0; i < reps; ++i) { sw.Restart(); a3j.Run(); a3t[i] = sw.ElapsedTicks; sw.Restart(); a4j.Run(); a4t[i] = sw.ElapsedTicks; sw.Restart(); d3j.Run(); d3t[i] = sw.ElapsedTicks; sw.Restart(); d4j.Run(); d4t[i] = sw.ElapsedTicks; } print( "Operation,float3 Time,float4 Timen" + "Add," + Median(a3t) + "," + Median(a4t) + "n" + "Dot," + Median(d3t) + "," + Median(d4t)); a3.Dispose(); b3.Dispose(); c3.Dispose(); a4.Dispose(); b4.Dispose(); c4.Dispose(); Application.Quit(); } static long Median(long[] values) { Array.Sort(values); return values[values.Length / 2]; } }
And here are the test results in the same environment:
| Operation | float3 Time | float4 Time |
|---|---|---|
| Add | 778890 | 775600 |
| Dot | 804040 | 794910 |
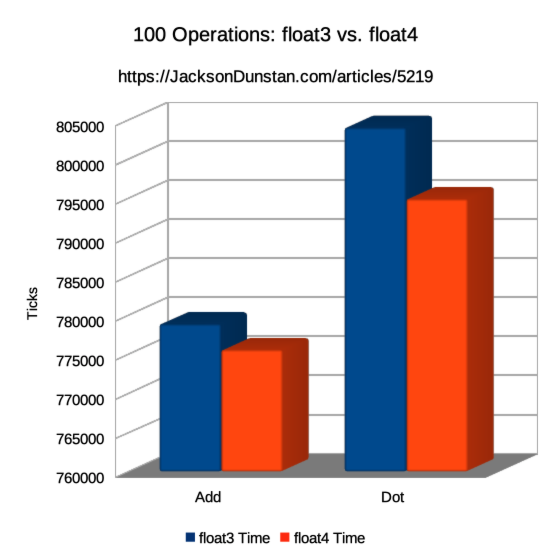
The CPU is now the bottleneck rather than memory I/O speed and this has lead to float4 running faster than float3.
In conclusion, using data types like float4 that match the data format of the CPU’s registers can dramatically improve the code that Burst compiles our jobs to. However, we should keep in mind that CPU instructions are not the only factor in performance. The additional memory I/O may result in slower performance by moving to float4. So, as always, it’s important to profile the actual game code with real game data to get a more complete picture than just Unity.Mathematics documentation and the Burst Inspector can give.
#1 by MechEthan on May 6th, 2019 ·
If you’re bored, any chance you want to add benchmarks for this running on an ARM-device / mobile-phone ? :D
#2 by MechEthan on May 7th, 2019 ·
I was dying to know, because its frustrating to me how Unity is multi-platform but Unity and the community focuses on desktop perf. (Like, its the most popular phone game engine but it will still burn through your battery at capped FPS on an idle scene?)
Anyway, looks like float4 on iPhone is generally better for lots of Add operations and generally worse for Dot operations regardless of how quantity.
#3 by MechEthan on May 7th, 2019 ·
Bleh, wrong tag…
#4 by MechEthan on May 7th, 2019 ·
Further details:
– I ran each of the benchmarks 3x in a row on each phone and didn’t see any major deviations, so I just picked one of the results from each.
iPhone 6 running iOS 10.3.2
iPhone 8 Plus running iOS 12.2
Unity 2019.1.1f1
Packages:
Burst 1.0.0
Mathematics 1.0.1
#5 by jackson on May 7th, 2019 ·
Thanks for posting these stats! It’s great to have some ARM data points.