Math.Abs или Mathf.Abs или math.abs или что-то еще?
(Russian translation from English by Maxim Voloshin)
Ðедавно, читатель ÑпроÑил какой Ñамый быÑтрый ÑпоÑоб получить модуль чиÑла. И Ñ Ð¾Ð±Ð½Ð°Ñ€ÑƒÐ¶Ð¸Ð», что ÑущеÑтвует много ÑпоÑобов Ñделать Ñто в Unity! Ð¡ÐµÐ³Ð¾Ð´Ð½Ñ Ð¼Ñ‹ попробуем их вÑе и узнаем какой Ñамый быÑтрый.
Варианты
Сколько вÑего ÑпоÑобов получить модуль чиÑла Ñ Ð¿Ð»Ð°Ð²Ð°ÑŽÑ‰ÐµÐ¹ точкой? Давайте поÑчитаем:
a = System.Math.Math.Abs(f);a = UnityEngine.Mathf.Abs(f);a = Unity.Mathematics.math.abs(f);if (f >= 0) a = f; else a = -f;a = f >= 0 ? f : -f;
Ðто довольно много! Варианты Ð¿Ð¾Ð»ÑƒÑ‡ÐµÐ½Ð¸Ñ Ð¼Ð¾Ð´ÑƒÐ»Ñ Ð²Ñ€ÑƒÑ‡Ð½ÑƒÑŽ (#3 и #4) очевидны, поÑтому, давайте углубимÑÑ Ð² оÑтальные варианты, чтобы увидеть, что именно они делают. Ðто Ð´ÐµÐºÐ¾Ð¼Ð¿Ð¸Ð»Ð¸Ñ€Ð¾Ð²Ð°Ð½Ð½Ð°Ñ Ð²ÐµÑ€ÑÐ¸Ñ Math.Abs:
[MethodImpl(4096)] public static extern float Abs(float value);
Она реализована в нативном коде, и Ñлед C# кончаетÑÑ. Давайте перейдем к варианту #2 и поÑмотрим на Mathf.Abs:
public static float Abs(float f) { return Math.Abs(f); }
Ðто вÑего лишь обертка над Math.Abs! ДвигаемÑÑ Ð´Ð°Ð»ÑŒÑˆÐµ, наÑтала очередь math.abs:
[MethodImpl(MethodImplOptions.AggressiveInlining)] public static float abs(float x) { return asfloat(asuint(x) & 0x7FFFFFFF); }
Как мы видим Ñто реализовано конвертированием float в uint, путем уÑтановки бита знака (0x7FFFFFFF Ñто ноль и 31 единица) в ноль, и конвертированием обратно в float. Чтобы разобрать конвертацию подробнее, поÑмотрим как работает asuint:
[MethodImpl(MethodImplOptions.AggressiveInlining)] public static uint asuint(float x) { return (uint)asint(x); }
ПроÑто обертка над asint:
[MethodImpl(MethodImplOptions.AggressiveInlining)] public static int asint(float x) { IntFloatUnion u; u.intValue = 0; u.floatValue = x; return u.intValue; }
asint иÑпользует объединение(union) чтобы обращатьÑÑ Ðº памÑти через пÑевдонимы(Ð¿Ð¾Ð»Ñ Ð¾Ð±ÑŠÐµÐ´Ð¸Ð½ÐµÐ½Ð¸Ñ) без Ð¸Ð·Ð¼ÐµÐ½ÐµÐ½Ð¸Ñ Ð±Ð¸Ñ‚Ð¾Ð² данных. Мы видели Ñтот прием ранее и даже знаем, что Ñто работает Ñ Burst. Вот как Unity Ñто реализует:
[StructLayout(LayoutKind.Explicit)] internal struct IntFloatUnion { [FieldOffset(0)] public int intValue; [FieldOffset(0)] public float floatValue; }
Ðто такой же подход, как мы видели ранее: одна и та же памÑÑ‚ÑŒ внутри Ñтруктуры иÑпользуетÑÑ Ð´Ð»Ñ int и float, таким образом тип может быть изменен без Ð·Ð°Ñ‚Ñ€Ð°Ð³Ð¸Ð²Ð°Ð½Ð¸Ñ Ð¿Ð°Ð¼Ñти.
Теперь вернемÑÑ Ð½Ð°Ð·Ð°Ð´ и поÑмотрим как uint преобразуетÑÑ Ð¾Ð±Ñ€Ð°Ñ‚Ð½Ð¾ в float:
[MethodImpl(MethodImplOptions.AggressiveInlining)] public static float asfloat(uint x) { return asfloat((int)x); }
И Ñнова, Ñто вÑего лишь перегрузка:
[MethodImpl(MethodImplOptions.AggressiveInlining)] public static float asfloat(int x) { IntFloatUnion u; u.floatValue = 0; u.intValue = x; return u.floatValue; }
ЗдеÑÑŒ проиÑходÑÑ‚ обратные Ð¿Ñ€ÐµÐ¾Ð±Ñ€Ð°Ð·Ð¾Ð²Ð°Ð½Ð¸Ñ Ñ Ð¸Ñпользованием того же объединениÑ.
Jobs
Далее, напишем неÑколько задач Burst компилÑтора, Ñ Ð¿Ð¾Ð¼Ð¾Ñ‰ÑŒÑŽ которых мы Ñможем протеÑтировать каждый подход, Ð½Ð°Ñ…Ð¾Ð´Ñ Ð¼Ð¾Ð´ÑƒÐ»ÑŒ чиÑла первого Ñлемента NativeArray:
[BurstCompile] struct SingleSystemMathAbsJob : IJob { public NativeArray<float> Values; public void Execute() { Values[0] = Math.Abs(Values[0]); } } [BurstCompile] struct SingleUnityEngineMathfAbsJob : IJob { public NativeArray<float> Values; public void Execute() { Values[0] = Mathf.Abs(Values[0]); } } [BurstCompile] struct SingleUnityMathematicsMathAbsJob : IJob { public NativeArray<float> Values; public void Execute() { Values[0] = math.abs(Values[0]); } } [BurstCompile] struct SingleIfJob : IJob { public NativeArray<float> Values; public void Execute() { float val = Values[0]; if (val >= 0) { Values[0] = val; } else { Values[0] = -val; } } } [BurstCompile] struct SingleTernaryJob : IJob { public NativeArray<float> Values; public void Execute() { float val = Values[0]; Values[0] = val >= 0 ? val : -val; } }
Ðемного позже мы поÑмотрим на результаты теÑта производительноÑти, а ÑÐµÐ¹Ñ‡Ð°Ñ Ð² аÑÑемблерный код, который Burst Ñкомпилировал Ð´Ð»Ñ ÐºÐ°Ð¶Ð´Ð¾Ð¹ задачи. Ðто покажет нам что в дейÑтвительноÑти выполнÑет процеÑÑор и прольет Ñвет на некоторые детали, Ñкрытые нативным кодом реализации Math.Abs.
Ð”Ð»Ñ Ð½Ð°Ñ‡Ð°Ð»Ð° код, идентичный и Ð´Ð»Ñ Math.Abs, и Ð´Ð»Ñ Mathf.Abs:
mov rax, qword ptr [rdi] movss xmm0, dword ptr [rax] movabs rcx, offset .LCPI0_0 andps xmm0, xmmword ptr [rcx] movss dword ptr [rax], xmm0 ret
ÐšÐ»ÑŽÑ‡ÐµÐ²Ð°Ñ Ñтрока здеÑÑŒ andps ÐºÐ¾Ñ‚Ð¾Ñ€Ð°Ñ Ð²Ñ‹Ð¿Ð¾Ð»Ð½Ñет & 0x7FFFFFFF, как мы видели в math.abs Ð´Ð»Ñ Ð¾Ñ‡Ð¸Ñтки знакового бита.
Теперь поÑмотрим, что Burst Ñкомпилировал Ð´Ð»Ñ math.abs:
mov rax, qword ptr [rdi] movss xmm0, dword ptr [rax] movabs rcx, offset .LCPI0_0 andps xmm0, xmmword ptr [rcx] movss dword ptr [rax], xmm0 ret
Как и ожидалоÑÑŒ, здеÑÑŒ также иÑпользуетÑÑ andps. ФактичеÑки Ñтот код идентичен коду Ð´Ð»Ñ Math.Abs и Mathf.Abs!
ВерÑÐ¸Ñ Ð²Ñ‹Ñ‡Ð¸ÑÐ»ÐµÐ½Ð¸Ñ Ð¼Ð¾Ð´ÑƒÐ»Ñ Ð²Ñ€ÑƒÑ‡Ð½ÑƒÑŽ, оÑÐ½Ð¾Ð²Ð°Ð½Ð½Ð°Ñ Ð½Ð° if:
mov rax, qword ptr [rdi] movss xmm0, dword ptr [rax] xorps xmm1, xmm1 ucomiss xmm1, xmm0 jbe .LBB0_2 movabs rcx, offset .LCPI0_0 xorps xmm0, xmmword ptr [rcx] movss dword ptr [rax], xmm0 .LBB0_2: ret
Ð’ Ñтой верÑии поÑвлÑетÑÑ Ð²ÐµÑ‚Ð²Ð»ÐµÐ½Ð¸Ðµ: jbe. Оно пропуÑкает запиÑÑŒ чего либо в маÑÑив в Ñлучае еÑли значение положительное. Ðто улучшение, потому что в таком Ñлучае запиÑываетÑÑ Ð¼ÐµÐ½ÑŒÑˆÐµ памÑти, но ветвление может привеÑти к неправильному прогнозу при загрузке команд процеÑÑора в кÑш и, Ñледовательно, неÑффективному иÑпользованию ЦПУ.
И, наконец, ручное вычиÑление, оÑнованное на тернарном операторе:
mov rax, qword ptr [rdi] movss xmm0, dword ptr [rax] movabs rcx, offset .LCPI0_0 andps xmm0, xmmword ptr [rcx] movss dword ptr [rax], xmm0 ret
Странно, но, Ñта верÑÐ¸Ñ Ð½Ðµ Ñодержит ветвление как оÑÐ½Ð¾Ð²Ð°Ð½Ð½Ð°Ñ Ð½Ð° if. ВмеÑто Ñтого, она идентична коду Ð´Ð»Ñ Math.Abs, Mathf.Abs, и math.abs! Каким то образом Burst Ñмог проанализировать и радикально изменить код Ñтой верÑии, но без иÑÐ¿Ð¾Ð»ÑŒÐ·Ð¾Ð²Ð°Ð½Ð¸Ñ if.
Performance
ÐаÑтало Ð²Ñ€ÐµÐ¼Ñ Ð¿Ñ€Ð¾Ñ‚ÐµÑтировать вÑе Ñти подходы, проанализировать производительноÑÑ‚ÑŒ и узнать какой из них Ñамый быÑтрый. Мы Ñделаем Ñто вычиÑлÑÑ Ð¼Ð¾Ð´ÑƒÐ»ÑŒ чиÑла Ð´Ð»Ñ ÐºÐ°Ð¶Ð´Ð¾Ð³Ð¾ Ñлемента NativeArray, заполненного Ñлучайными значениÑми:
using System; using System.Diagnostics; using Unity.Burst; using Unity.Collections; using Unity.Jobs; using Unity.Mathematics; using UnityEngine; [BurstCompile] struct SystemMathAbsJob : IJob { public NativeArray<float> Values; public void Execute() { for (int i = 0; i < Values.Length; ++i) { Values[i] = Math.Abs(Values[i]); } } } [BurstCompile] struct UnityEngineMathfAbsJob : IJob { public NativeArray<float> Values; public void Execute() { for (int i = 0; i < Values.Length; ++i) { Values[i] = Mathf.Abs(Values[i]); } } } [BurstCompile] struct UnityMathematicsMathAbsJob : IJob { public NativeArray<float> Values; public void Execute() { for (int i = 0; i < Values.Length; ++i) { Values[i] = math.abs(Values[i]); } } } [BurstCompile] struct IfJob : IJob { public NativeArray<float> Values; public void Execute() { for (int i = 0; i < Values.Length; ++i) { float val = Values[i]; if (val >= 0) { Values[i] = val; } else { Values[i] = -val; } } } } [BurstCompile] struct TernaryJob : IJob { public NativeArray<float> Values; public void Execute() { for (int i = 0; i < Values.Length; ++i) { float val = Values[i]; Values[i] = val >= 0 ? val : -val; } } } class TestScript : MonoBehaviour { void Start() { NativeArray<float> values = new NativeArray<float>( 100000, Allocator.TempJob); for (int i = 0; i < values.Length; ++i) { values[i] = UnityEngine.Random.Range(float.MinValue, float.MaxValue); } SystemMathAbsJob systemMathAbsJob = new SystemMathAbsJob { Values = values }; UnityEngineMathfAbsJob unityEngineMathfAbsJob = new UnityEngineMathfAbsJob { Values = values }; UnityMathematicsMathAbsJob unityMathematicsMathAbsJob = new UnityMathematicsMathAbsJob { Values = values }; IfJob ifJob = new IfJob { Values = values }; TernaryJob ternaryJob = new TernaryJob { Values = values }; // Прогрев job system systemMathAbsJob.Run(); unityEngineMathfAbsJob.Run(); unityMathematicsMathAbsJob.Run(); ifJob.Run(); ternaryJob.Run(); Stopwatch sw = Stopwatch.StartNew(); systemMathAbsJob.Run(); long systemMathAbsTicks = sw.ElapsedTicks; sw.Restart(); unityEngineMathfAbsJob.Run(); long unityEngineMathfAbsTicks = sw.ElapsedTicks; sw.Restart(); unityMathematicsMathAbsJob.Run(); long unityMathematicsMathAbsTicks = sw.ElapsedTicks; sw.Restart(); ifJob.Run(); long ifTicks = sw.ElapsedTicks; sw.Restart(); ternaryJob.Run(); long ternaryTicks = sw.ElapsedTicks; values.Dispose(); print( "Function,Ticksn" + "System.Math.Abs," + systemMathAbsTicks + "n" + "UnityEngine.Mathf.Abs," + unityEngineMathfAbsTicks + "n" + "Unity.Mathematics.Math.Abs," + unityMathematicsMathAbsTicks + "n" + "If," + ifTicks + "n" + "Ternary," + ternaryTicks ); } }
ТеÑÑ‚Ð¾Ð²Ð°Ñ Ð¼Ð°ÑˆÐ¸Ð½Ð° на которой запуÑкалÑÑ Ñ‚ÐµÑÑ‚:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.14.6
- Unity 2018.4.3f1
- macOS Standalone
- .NET 4.x scripting runtime version and API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
| Ð¤ÑƒÐ½ÐºÑ†Ð¸Ñ | Тики |
|---|---|
| System.Math.Abs | 253 |
| UnityEngine.Mathf.Abs | 198 |
| Unity.Mathematics.Math.Abs | 195 |
| If | 517 |
| Ternary | 1447 |
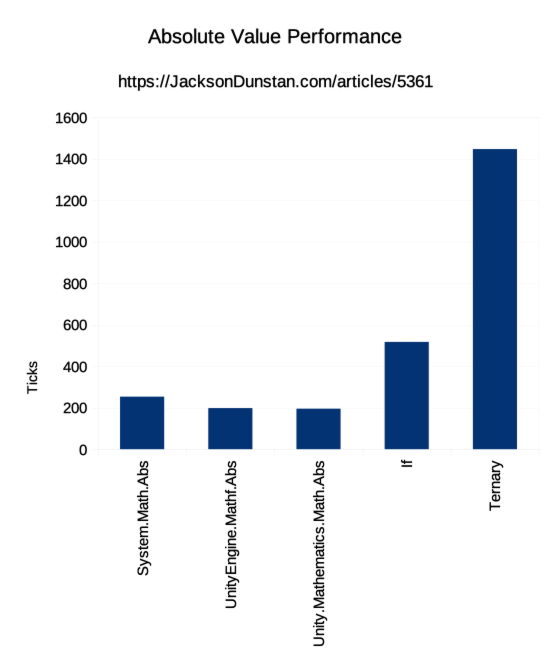
ПроизводительноÑÑ‚ÑŒ оказалаÑÑŒ неожиданно разной! Ранее мы видели, что четыре варианта из пÑти имеют идентичный аÑÑемблерный код. Однако, мы видим, что только Math.Abs, Mathf.Abs, и math.Abs имеют примерно одинаковую производительноÑÑ‚ÑŒ. ВерÑÐ¸Ñ Ñ Ñ‚ÐµÑ€Ð½Ð°Ñ€Ð½Ñ‹Ð¼ операторам должна иметь такую же производительноÑÑ‚ÑŒ, но Ñто не так. ФактичеÑки, ее производительноÑÑ‚ÑŒ в 10 раз хуже!
Ð”Ð»Ñ Ñ‚Ð¾Ð³Ð¾ чтобы понÑÑ‚ÑŒ, повлиÑл ли цикл, добавленный в теÑÑ‚, поÑмотрим аÑÑемблерный код Ð´Ð»Ñ Ñтих задач в Burst инÑпекторе.
Math.Abs, Mathf.Abs, и math.abs:
movsxd rax, dword ptr [rdi + 8] test rax, rax jle .LBB0_8 mov rcx, qword ptr [rdi] cmp eax, 8 jae .LBB0_3 xor edx, edx jmp .LBB0_6 .LBB0_3: mov rdx, rax and rdx, -8 lea rsi, [rcx + 16] movabs rdi, offset .LCPI0_0 movaps xmm0, xmmword ptr [rdi] mov rdi, rdx .p2align 4, 0x90 .LBB0_4: movups xmm1, xmmword ptr [rsi - 16] movups xmm2, xmmword ptr [rsi] andps xmm1, xmm0 andps xmm2, xmm0 movups xmmword ptr [rsi - 16], xmm1 movups xmmword ptr [rsi], xmm2 add rsi, 32 add rdi, -8 jne .LBB0_4 cmp rdx, rax je .LBB0_8 .LBB0_6: sub rax, rdx lea rcx, [rcx + 4*rdx] movabs rdx, offset .LCPI0_0 movaps xmm0, xmmword ptr [rdx] .p2align 4, 0x90 .LBB0_7: movss xmm1, dword ptr [rcx] andps xmm1, xmm0 movss dword ptr [rcx], xmm1 add rcx, 4 dec rax jne .LBB0_7 .LBB0_8: ret
If:
movsxd rax, dword ptr [rdi + 8] test rax, rax jle .LBB0_26 mov r8, qword ptr [rdi] cmp eax, 8 jae .LBB0_3 xor edx, edx jmp .LBB0_22 .LBB0_3: mov rdx, rax and rdx, -8 xorps xmm0, xmm0 movabs rsi, offset .LCPI0_0 movaps xmm1, xmmword ptr [rsi] mov rsi, r8 mov rdi, rdx .p2align 4, 0x90 .LBB0_4: movups xmm3, xmmword ptr [rsi] movups xmm2, xmmword ptr [rsi + 16] movaps xmm4, xmm3 cmpltps xmm4, xmm0 pextrb ecx, xmm4, 0 test cl, 1 jne .LBB0_5 pextrb ecx, xmm4, 4 test cl, 1 jne .LBB0_7 .LBB0_8: pextrb ecx, xmm4, 8 test cl, 1 jne .LBB0_9 .LBB0_10: pextrb ecx, xmm4, 12 test cl, 1 je .LBB0_12 .LBB0_11: shufps xmm3, xmm3, 231 xorps xmm3, xmm1 movss dword ptr [rsi + 12], xmm3 .LBB0_12: movaps xmm3, xmm2 cmpltps xmm3, xmm0 pextrb ecx, xmm3, 0 test cl, 1 jne .LBB0_13 pextrb ecx, xmm3, 4 test cl, 1 jne .LBB0_15 .LBB0_16: pextrb ecx, xmm3, 8 test cl, 1 jne .LBB0_17 .LBB0_18: pextrb ecx, xmm3, 12 test cl, 1 jne .LBB0_19 .LBB0_20: add rsi, 32 add rdi, -8 jne .LBB0_4 jmp .LBB0_21 .p2align 4, 0x90 .LBB0_5: movaps xmm5, xmm3 xorps xmm5, xmm1 movss dword ptr [rsi], xmm5 pextrb ecx, xmm4, 4 test cl, 1 je .LBB0_8 .LBB0_7: movshdup xmm5, xmm3 xorps xmm5, xmm1 movss dword ptr [rsi + 4], xmm5 pextrb ecx, xmm4, 8 test cl, 1 je .LBB0_10 .LBB0_9: movaps xmm5, xmm3 movhlps xmm5, xmm5 xorps xmm5, xmm1 movss dword ptr [rsi + 8], xmm5 pextrb ecx, xmm4, 12 test cl, 1 jne .LBB0_11 jmp .LBB0_12 .p2align 4, 0x90 .LBB0_13: movaps xmm4, xmm2 xorps xmm4, xmm1 movss dword ptr [rsi + 16], xmm4 pextrb ecx, xmm3, 4 test cl, 1 je .LBB0_16 .LBB0_15: movshdup xmm4, xmm2 xorps xmm4, xmm1 movss dword ptr [rsi + 20], xmm4 pextrb ecx, xmm3, 8 test cl, 1 je .LBB0_18 .LBB0_17: movaps xmm4, xmm2 movhlps xmm4, xmm4 xorps xmm4, xmm1 movss dword ptr [rsi + 24], xmm4 pextrb ecx, xmm3, 12 test cl, 1 je .LBB0_20 .LBB0_19: shufps xmm2, xmm2, 231 xorps xmm2, xmm1 movss dword ptr [rsi + 28], xmm2 add rsi, 32 add rdi, -8 jne .LBB0_4 .LBB0_21: cmp rdx, rax je .LBB0_26 .LBB0_22: lea rcx, [r8 + 4*rdx] sub rax, rdx xorps xmm0, xmm0 movabs rdx, offset .LCPI0_0 movaps xmm1, xmmword ptr [rdx] .p2align 4, 0x90 .LBB0_25: movss xmm2, dword ptr [rcx] ucomiss xmm0, xmm2 jbe .LBB0_24 xorps xmm2, xmm1 movss dword ptr [rcx], xmm2 .LBB0_24: add rcx, 4 dec rax jne .LBB0_25 .LBB0_26: ret
Тернарный оператор:
xor eax, eax movabs rcx, offset .LCPI0_0 movaps xmm0, xmmword ptr [rcx] .p2align 4, 0x90 .LBB0_2: mov rcx, qword ptr [rdi] movss xmm1, dword ptr [rcx + 4*rax] andps xmm1, xmm0 movss dword ptr [rcx + 4*rax], xmm1 inc rax movsxd rcx, dword ptr [rdi + 8] cmp rax, rcx jl .LBB0_2 .LBB0_3: ret
Мы видим что код if значительно длиннее и намного Ñложнее Math.Abs, Mathf.Abs, и math.abs. Так что не удивительно, что они примерно вдвое быÑтрее.
ВерÑÐ¸Ñ Ð´Ð»Ñ Ñ‚ÐµÑ€Ð½Ð°Ñ€Ð½Ð¾Ð³Ð¾ оператора, Ñ Ð´Ñ€ÑƒÐ³Ð¾Ð¹ Ñтороны, безуÑловно ÑÐ°Ð¼Ð°Ñ ÐºÐ¾Ñ€Ð¾Ñ‚ÐºÐ°Ñ Ð¸Ð· трех, приведенных выше. Ðто проÑтой цикл, выполнÑющий наложение маÑки. Ðо почему же он такой медленный? Возможно, Ñто проиÑходит потому что задача выполнÑетÑÑ Ð¿Ð¾Ñледней, но Ð¿ÐµÑ€ÐµÐ½Ð¾Ñ ÐµÐµ в начало теÑта не влиÑет на результаты. Как ни Ñтранно, проблема в том, что пропуÑк запиÑи уже положительных значений, дает побочный Ñффект. Больше времени тратитÑÑ Ð½Ð° Ñам цикл и потенциальные промахи в предÑказании команд из-за уÑловного перехода и меньше времени на вычиÑление значений.
Заключение
Когда выполнÑетÑÑ Ñ‚Ð¾Ð»ÑŒÐºÐ¾ одна операциÑ, Burst компилирует идентичный код Ð´Ð»Ñ Math.Abs, Mathf.Abs, math.abs и даже тернарного оператора. Когда иÑпользуетÑÑ if, Burst генерирует инÑтрукции уÑловного перехода. Так что в данном Ñлучае, вÑе подходы равны кроме оÑнованного на if, который лучше избежать.
Когда модуль чиÑла находитÑÑ Ð² цикле, Burst генерирует идентичный машинный код Ð´Ð»Ñ Ñ‚Ñ€ÐµÑ… Ñамых быÑтрых подходов: Math.Abs, Mathf.Abs, и math.abs. ИÑпользование if примерно в 2 раза медленнее, а тернарный оператор в 10 раз. Оба лучше не иÑпользовать.
Ð’ итоге, лучше вÑего будет иÑпользовать, Math.Abs, Mathf.Abs, и math.abs.