Loops With int and uint
AS3 has two integer types: int and uint. In my experience, most AS3 programmers just use int everywhere and ignore uint. This is usually acceptable as the need for unsigned integers is rare compared to their signed counterparts. However, there are significant performance differences between the two. Read on for the impact of uint on your loops. The original version of this article’s performance test contained a small-but-critical error that led to a lot of incorrect analysis and results. This version of the article has been corrected.
One common uint you’ll run across in AS3 is the length property of Array and Vector. While you should almost always cache this expensive getter call as a local variable, should you cache it as an int or a uint? To preserve compatibility with lengths greater than 2 billion long, you should keep it as a uint to avoid using the sign bit. This case is extremely rare though, as an Array or Vector that large takes up at least 2 GB of RAM. The more important question is which will run faster.
With speed in mind, I’ve designed a small performance test to see the performance in various scenarios:
- A
forloop that pre-increments (++x) anintiterator - A
forloop that post-increments (x++) aintiterator - A
forloop that pre-increments (++x) anuintiterator - A
forloop that post-increments (x++) auintiterator - A
forloop that adds one (x+=1) anintiterator - A
forloop that adds one (x+=1) auintiterator - A
forloop that compares anintiterator with auintcheck (i.e.int < uint) - A
forloop that compares auintiterator with anintcheck (i.e.uint < int) - A
forloop that pre-decrements (--x) the length in the check part - A
forloop that pre-decrements (--x) the length in the counting part
package { import flash.display.*; import flash.utils.*; import flash.text.*; public class IntUintLoops extends Sprite { public function IntUintLoops() { var logger:TextField = new TextField(); logger.autoSize = TextFieldAutoSize.LEFT; addChild(logger); var beforeTime:int; var afterTime:int; var SIZEINT:int = 100000000; var SIZEUINT:uint = SIZEINT; var i:int; var u:uint; logger.text = "Method,Time\n"; beforeTime = getTimer(); for (i = 0; i < SIZEINT; ++i) { } afterTime = getTimer(); logger.appendText("++int," + (afterTime-beforeTime) + "\n"); beforeTime = getTimer(); for (u = 0; u < SIZEUINT; ++u) { } afterTime = getTimer(); logger.appendText("++uint," + (afterTime-beforeTime) + "\n"); beforeTime = getTimer(); for (i = 0; i < SIZEINT; i++) { } afterTime = getTimer(); logger.appendText("int++," + (afterTime-beforeTime) + "\n"); beforeTime = getTimer(); for (u = 0; u < SIZEUINT; u++) { } afterTime = getTimer(); logger.appendText("uint++," + (afterTime-beforeTime) + "\n"); beforeTime = getTimer(); for (i = 0; i < SIZEINT; i+=1) { } afterTime = getTimer(); logger.appendText("int+=1," + (afterTime-beforeTime) + "\n"); beforeTime = getTimer(); for (u = 0; u < SIZEUINT; u+=1) { } afterTime = getTimer(); logger.appendText("uint+=1," + (afterTime-beforeTime) + "\n"); beforeTime = getTimer(); for (i = 0; i < SIZEUINT; i++) { } afterTime = getTimer(); logger.appendText("int iterator w/ uint check," + (afterTime-beforeTime) + "\n"); beforeTime = getTimer(); for (u = 0; u < SIZEINT; u++) { } afterTime = getTimer(); logger.appendText("uint iterator w/ int check," + (afterTime-beforeTime) + "\n"); beforeTime = getTimer(); for (i = 0; SIZEINT--; i++) { } afterTime = getTimer(); SIZEINT = SIZEUINT; logger.appendText("length decrement in check," + (afterTime-beforeTime) + "\n"); beforeTime = getTimer(); for (i = 0; SIZEINT; i++, --SIZEINT) { } afterTime = getTimer(); SIZEINT = SIZEUINT; logger.appendText("length decrement in post," + (afterTime-beforeTime) + "\n"); } } }
I ran this performance test with the following environment:
- Flex SDK (MXMLC) 4.1.0.16076, compiling in release mode (no debugging or verbose stack traces)
- Release version of Flash Player 10.3.181.26
- 2.4 Ghz Intel Core i5
- Mac OS X 10.6.8
And got these results:
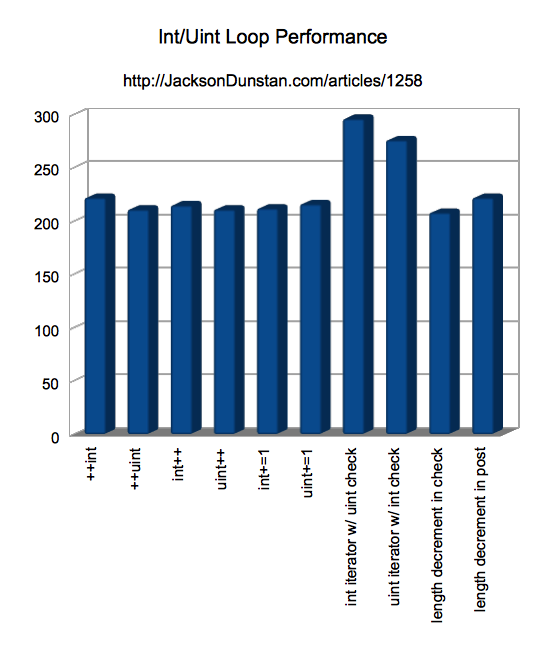
| Method | Time |
|---|---|
| ++int | 222 |
| ++uint | 211 |
| int++ | 215 |
| uint++ | 211 |
| int+=1 | 212 |
| uint+=1 | 216 |
| int iterator w/ uint check | 296 |
| uint iterator w/ int check | 276 |
| length decrement in check | 208 |
| length decrement in post | 222 |
Here are the same results in graph form:
Below is the bytecode generated by the compiler for each test. There are significant variations between each test, but the performance results don't show much, if any, difference. It is likely that the JIT is stepping in to optimize some of these tests, but it's hard to tell which. Of note is how "int iterator w/ uint check" is deceptively identical to "++int" and "int++", even though it consistently runs about one third slower!
++int
pushbyte 0
setlocal 6
jump L1
L2:
label
inclocal_i 6
L1:
getlocal 6
getlocal 4
iflt L2
++uint
pushbyte 0
convert_u
setlocal 7
jump L3
L4:
label
getlocal 7
increment
convert_u
setlocal 7
L3:
getlocal 7
getlocal 5
iflt L4
int++
pushbyte 0
setlocal 6
jump L5
L6:
label
inclocal_i 6
L5:
getlocal 6
getlocal 4
iflt L6
uint++
pushbyte 0
convert_u
setlocal 7
jump L7
L8:
label
getlocal 7
increment
convert_u
setlocal 7
L7:
getlocal 7
getlocal 5
iflt L8
int+=1
pushbyte 0
setlocal 6
jump L9
L10:
label
getlocal 6
pushbyte 1
add
convert_i
setlocal 6
L9:
getlocal 6
getlocal 4
iflt L10
uint+=1
pushbyte 0
convert_u
setlocal 7
jump L11
L12:
label
getlocal 7
pushbyte 1
add
convert_u
setlocal 7
L11:
getlocal 7
getlocal 5
iflt L12
int iterator w/ uint check
pushbyte 0
setlocal 6
jump L13
L14:
label
inclocal_i 6
L13:
getlocal 6
getlocal 5
iflt L14
uint iterator w/ int check
pushbyte 0
convert_u
setlocal 7
jump L15
L16:
label
getlocal 7
increment
convert_u
setlocal 7
L15:
getlocal 7
getlocal 4
iflt L16
length decrement in check
pushbyte 0
setlocal 6
jump L17
L18:
label
inclocal_i 6
L17:
getlocal 4
dup
decrement_i
setlocal 4
iftrue L18
length decrement in post
pushbyte 0
setlocal 6
jump L19
L20:
label
inclocal_i 6
getlocal 4
decrement_i
setlocal 4
L19:
getlocal 4
iftrue L20In any case, the performance of the mixed loops—int iterator with uint check or visa versa—exhibit far worse performance than any of the other loops. As the bytecode shows, they are using the stack more (pushbyte 0) and using the general add instruction rather than the special-purpose increment instructions. This has led to an astounding 6x performance drop compared to all of the alternatives.
As for the others, there isn't much difference. Remember that this test runs 100 million iterations of each loop, so differences of a couple of milliseconds are likely just statistical noise.
In conclusion, feel free to use either int or uint in your loops, but be careful to not mix them by having an int iterator and a uint length check or visa versa. Happy looping!
#1 by skyboy on June 20th, 2011 ·
There are also a couple other methods to loop:
for (var i:int; len–; ++i);
for (var i:int; len; ++i, –len);
They both use the same number of variables and will have different performances compared to using a .. comparison. I also suspect that performance will vary more dramatically between int/uint.
I’m not sure how you’re getting inclocal_i for the uint, as i’m relatively certain that method will convert a uint to an int internally, leading to bugs elsewhere. The bytecode I’ve gotten from the compiler was always getlocal/increment opcode(s)/setlocal: from a short performance test I performed in the debug player I noticed the multiple code method took less time than the single code method; I’m relatively certain nJIT is getting in on it there, though.
#2 by jackson on June 20th, 2011 ·
The article had a major bug in it: the
uintvariable was declared as anint! I probably should have named it something that didn’t “read” like “uint”:Anyhow, I’ve corrected the error and updated the article with all new results, analysis, and conclusions. I’ve also included your two test cases, though they didn’t make much difference. As for the bytecode, it makes much more sense now that
uis auint. :)Thank you very much for pointing this out. It could have very well been one of those articles where no one tells me I have a critical error for an entire year…
#3 by skyboy on June 20th, 2011 ·
Wow, that’s surprising. Either nJIT is optimizing away the float increment to an int increment or the increment op function checks for float/int types and reacts accordingly.
Though, you did miss two cases: length being a uint while decrementing it. Based on my own tests, there should be a staggering difference with:
for (var i:int, len:uint = ...; len--; ++i);compared to:for (var i:int, len:int = ...; len--; ++i);#4 by jackson on June 20th, 2011 ·
OK, I ran those too on the same test machine:
The “length decrement in check” version is apparently quite horrible when the length is a
uint. Here’s the bytecode:pushbyte 0 setlocal 6 jump L21 L22: label inclocal_i 6 L21: getlocal 5 convert_d dup decrement convert_u setlocal 5 iftrue L22And there you have it: a conversion through float at the
convert_dline. This never appears in any other version, so it’s strange that it appears here.#5 by Azzatai on June 28th, 2011 ·
Running your test code on my machine I noticed that my times for the +=1 operations are in line with all the other loops. I think you must have mistaken the int+=1,214 to be 1214, but it is 214 because the 1 comes from your string. :)
#6 by jackson on June 28th, 2011 ·
I think you’re right that I mistook the “1” from “+=1” as a thousands digit. :O
I re-ran the test, updated the results table and graph, and removed the erroneous bit of analysis at the end warning to not use
+=1.Thanks for letting me know about this!
#7 by Epsz on June 30th, 2011 ·
If you want to know when the JIT comes into play, you should do incrementally larger tests and graph the resulting time(size of the tests on the Y axis, time on the X). There should be a visible leap in the curve when/if the JIT starts doing it’s thing.