Exotic CPU Instructions
Programming in high-level languages like C# often presents the illusion that the CPU is only capable of a few primitive operations like “add,” “multiply,” “push,” “pop,” and “move.” After all, those are the primitive operations that we write all of our C# code with. The reality is quite different. Modern CPUs have hundreds of instructions for tons of special-purpose operations. Entire algorithms in C# are built right into the CPU and can be executed with one instruction. Today we’ll look at some of these exotic instructions as a reminder of what CPUs can really do and see how we can tap into this potential.
Nearly every relevant CPU these days is either an x86 or ARM variant. It’s well worth our time to get to know what the CPUs that execute our code can do. Intel and ARM helpfully provide PDF documents describing every single function for x86 and ARM, so it’s easy to browse through them. Many are obvious instructions like “add” and “move,” but many more are quite interesting and powerful for practical purposes. Some general-purpose instructions like these include:
- MADD: a combined “multiply and add” useful for interpolation and extrapolation
- Reciprocal: 1/x, but faster than a divide instruction
- Min and Max: common operations without the need for an expensive branch instruction like
ifgenerates - Average: another common operation made faster by combining addition and division
Then there’s a whole ton of instructions that fall under the SIMD umbrella term. The acronym stands for “Single Instruction, Multiple Data” and allows us to perform the same operation on multiple variables in one instruction. For example, we can add a vector to another vector in one instruction rather than executing four addition instructions. This is made possible because the memory of these vectors is laid out precisely as X then Y then Z then W so CPUs can assume an ordering and perform the operation efficiently. The same goes for tons of other operations like multiplication, division, etc.
SIMD instructions can’t be used directly from C# code. IL2CPP is unlikely to generate C++ code that a C++ compiler will “auto-vectorize” by using SIMD. However, Unity’s upcoming Burst compiler will attempt to generate SIMD instructions for the contents of jobs. In the meantime and for non-job code, we can still call into C++ code and use it to either write inline assembly or call compiler instrinsics that map directly to CPU instructions.
Beyond SIMD there are even more specialized instructions for exceptionally common and well-defined algorithms. For example, modern CPUs include support for cryptography directly on the chip. So there’s no need to write an algorithm using a bunch of other instructions when you can simply execute one instruction to encrypt or decrypt a block of data with AES or hash with SHA1 or SHA256. The Burst compiler doesn’t aim to support cryptography instructions, so we’ll still need to call into C or C++ code to execute these.
To illustrate the point, let’s use x86’s aesenc instruction to perform AES encryption. This has been available on x86 chips by Intel and AMD since 2010 as part of the AES-NI instruction set. This includes AMD’s Janguar chips used on both Xbox One and PlayStation 4. Likewise, ARM chips have been supporting AES since 2011 when the 64-bit ARMv8-A architecture was released. This includes every iPhone since the 5S and many Android phones such as the Samsung Galaxy S6.
Let’s start out by writing the C code that uses these special instructions. This code will simply AES-encrypt the same 16-byte block of data over and over to gauge performance. This isn’t really a productive use of CPU time, but it does test how fast the aesenc instruction is. To do this, we’ll call the _mm_aesenc_si128 compiler intrinsic, which is used just like any other function. We’ll also use the 128-bit integer data type __m128i since blocks and keys are 128 bits in the AES algorithm. The same goes for the decryption side.
#include <emmintrin.h> #include <wmmintrin.h> #include <stdint.h> void AesEncrypt( __m128i* __restrict plaintext, __m128i* __restrict ciphertext, __m128i* __restrict key, int32_t reps) { for (int32_t i = 0; i < reps; ++i) { *ciphertext = _mm_aesenc_si128(*plaintext, *key); } } void AesDecrypt( __m128i* __restrict ciphertext, __m128i* __restrict plaintext, __m128i* __restrict key, int32_t reps) { for (int32_t i = 0; i < reps; ++i) { // edit: the first parameter should have been *ciphertext *plaintext = _mm_aesdec_si128(*plaintext, *key); } }
Compiling this in “release” mode with Xcode 9.3 and the -maes compiler option (to get access to AES-NI), we get the following assembly output:
; AesEncrypt
movq %rsp, %rbp
testl %ecx, %ecx
jle LBB0_2
movdqa (%rdi), %xmm0
aesenc (%rdx), %xmm0
movdqa %xmm0, (%rsi)
LBB0_2:
popq %rbp
retq
; AesDecrypt
movq %rsp, %rbp
testl %ecx, %ecx
jle LBB1_4
movdqa (%rdx), %xmm1
movdqa (%rsi), %xmm0
LBB1_2:
aesdec %xmm1, %xmm0
decl %ecx
jne LBB1_2
movdqa %xmm0, (%rsi)
LBB1_4:
popq %rbp
retqThese are really simple functions that are basically just loops that call either aesenc to encrypt or aesdec to decrypt. This should perform very well, but we’ll need to try it out below to see.
Now let’s write the C# version of this, including the benchmarking code to measure performance. We’ll use AesManaged, the C# implementation of the AES algorithm and call CreateEncryptor and CreateDecryptor to get ICryptoTransform interfaces that can perform the encryption and decryption. Then we’ll call TransformBlock on them repeatedly, just like the above loops in C.
It’s worth noting that this is a little unfair to the C# side since interfaces aren’t strictly necessary and there could be a TransformSingleBlock that specialized to only encrypt or decrypt one block of data. We’d have to find an alternative AES implementation or write our own in order to make this happen though since we don’t control the .NET APIs.
Let’s look at the C# side:
using System.Runtime.InteropServices; using System.Security.Cryptography; using UnityEngine; public unsafe class TestScript : MonoBehaviour { [DllImport("SpecialCpuInstructions")] private static extern void AesEncrypt( byte* plaintext, byte* ciphertext, byte* key, int reps); [DllImport("SpecialCpuInstructions")] private static extern void AesDecrypt( byte* ciphertext, byte* plaintext, byte* key, int reps); void Start() { // Test parameters const int numCryptoOps = 1000000; // Setup const int blockSize = 16; byte[] plaintext = new byte[blockSize]; byte[] ciphertext = new byte[blockSize]; byte[] key = new byte[blockSize]; byte[] iv = new byte[blockSize]; AesManaged aes = new AesManaged { Key = key, IV = iv }; ICryptoTransform encryptor = aes.CreateEncryptor(); ICryptoTransform decryptor = aes.CreateDecryptor(); // C# Encrypt System.Diagnostics.Stopwatch sw = System.Diagnostics.Stopwatch.StartNew(); for (int i = 0; i < numCryptoOps; ++i) { encryptor.TransformBlock(plaintext, 0, blockSize, ciphertext, 0); } long csharpEncryptTime = sw.ElapsedMilliseconds; // C# Decrypt sw.Reset(); sw.Start(); for (int i = 0; i < numCryptoOps; ++i) { decryptor.TransformBlock(ciphertext, 0, blockSize, plaintext, 0); } long csharpDecryptTime = sw.ElapsedMilliseconds; // Intrinsics Encrypt sw.Reset(); sw.Start(); fixed (byte* pPlaintext = plaintext) { fixed (byte* pCiphertext = ciphertext) { fixed (byte* pKey = key) { AesEncrypt(pPlaintext, pCiphertext, pKey, numCryptoOps); } } } long intEncryptTime = sw.ElapsedMilliseconds; // Intrinsics Decrypt sw.Reset(); sw.Start(); fixed (byte* pPlaintext = plaintext) { fixed (byte* pCiphertext = ciphertext) { fixed (byte* pKey = key) { AesDecrypt(pCiphertext, pPlaintext, pKey, numCryptoOps); } } } long intDecryptTime = sw.ElapsedMilliseconds; // Report const int size = numCryptoOps * blockSize; Debug.Log( "Method,Encrypt,Decryptn" + $"C#,{size/csharpEncryptTime},{size/csharpDecryptTime}n" + $"Intrinsics,{size/intEncryptTime},{size/intDecryptTime}"); } }
Running this on macOS 10.13.5 with a 2.7 GHz Intel Core i7 in an IL2CPP build from Unity 2018.1.0f2, we get the following results:
| Method | Encrypt | Decrypt |
|---|---|---|
| C# | 77669 | 59479 |
| Intrinsics | 842105 | 16000000 |
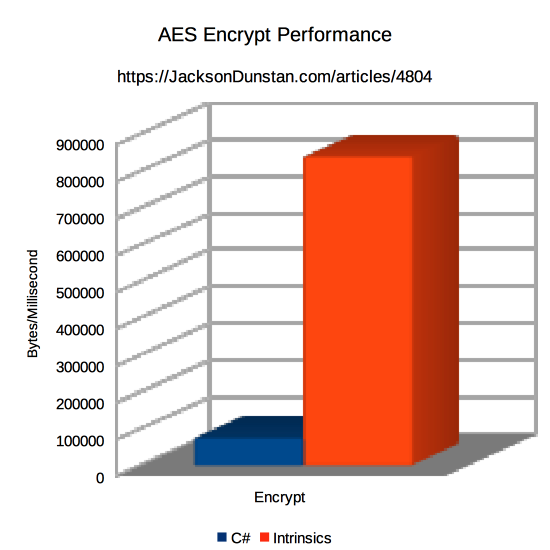
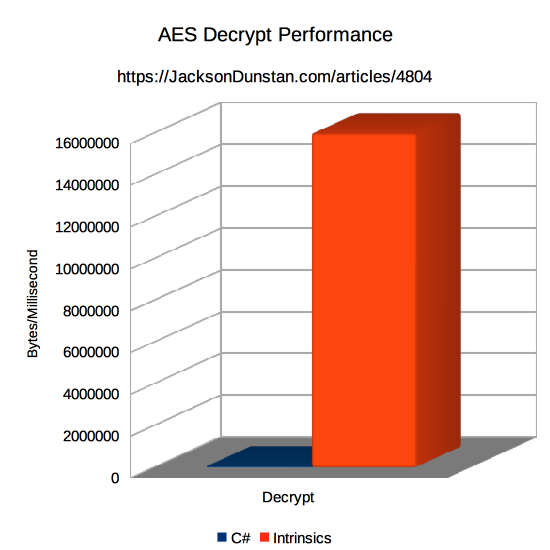
C# is very much outperformed for both encryption and decryption by the combination of P/Invoke, the C compiler, and intrinsics that gain direct access to the special-purpose CPU instructions. Encryption is 11x faster than C# and decryption is 269x faster! Again, the test is somewhat unfair as the C# side could be optimized further, but it illustrates the wide performance gap between algorithms implemented by general-purpose instructions like “add” and “divide” and algorithms implemented in the hardware and executed with a single instruction.
Implementing this test including the C code took all of a few minutes, so it’s well within our reach as Unity programmers. It’s worth our time to peruse through the available CPU instructions and gain some familiarity with them. You never know what gems you’ll find there!
#1 by Alexey on June 25th, 2018 ·
Hi, thank you for your post.
I have a question:
How about a overhad to load the C library? You are calling extern method 2 million times. This is defenetly reflected on performance.
I was wrote similar code on Rust and C# and test them. And C# code very much outperformed in comparasion with Rust. Then I wrote a stopwatch on Rust and saw that the program execution takes 40-50 milliseconds, and in C# 650-700 is fixed.
#2 by jackson on June 25th, 2018 ·
The test actually just calls each extern method one time and then they loop one million times each. This is definitely faster than calling the extern methods a total of two million times as it avoids the function call overhead. Exactly how much overhead will depend on the platform. For example, iOS, Android, and WebGL will each behave differently.
In general, if you’re calling into native code to gain access to these kinds of CPU instructions then it’s probably best to have the native function you call do a relatively large amount of work so that the overhead of the function call is relatively small. For example, rather than exposing a C function that encrypts one block with AES, it’d be better to expose a C function that encrypts an entire byte array.
#3 by Mandar on June 25th, 2018 ·
In AesDecrypt, it should be
*plaintext = _mm_aesdec_si128(*ciphertext, *key);
#4 by jackson on June 26th, 2018 ·
Good catch! I’ve updated the article to note the typo.