NativeChunkedList<T>
Today’s article is about a new native collection type: NativeChunkedList<T>. This type is great when you need a dynamically-resizable array that’s fast to add to and doesn’t waste a lot of memory. Read on to see how it’s implemented, see the performance report, and get the source code.
NativeList
NativeList<T> is Unity’s native version of the C# List<T> type: a dynamically-resizable array. It’s part of the com.unity.collections package that comes with Unity’s ECS, which is still in Preview as of Unity 2018.2. This type stores elements in a single native/unmanaged array, just like NativeArray<T> does. That array has a capacity which is equal to or greater than the number of elements stored, known as the length. When an element is added and there is spare capacity, it’s simply added to the end. If there’s no more spare capacity, a new array with twice the capacity is allocated, all the elements are copied over, the old array is freed, and the element is added to the end.
The performance characteristics of this approach are usually quite good. Accessing the list is just as fast as accessing a NativeArray<T> because it is represented exactly the same: just one array. However, growing the list is quite expensive as it requires copying the whole list to a new array. Likewise, the doubling of capacity can result in quite a lot of waste. For example, if an element is added to a full list with 1024 capacity then the new capacity will be 2048 even though room for only 1025 elements is needed.
Chunked List Approach
Today’s approach aims to solve these issues with NativeList<T>. Like how Unity’s ECS stores components, NativeChunkedList<T> stores its components in “chunks.” Each chunk is simply an array of elements. It then also stores an array of pointers to the chunks.
Here’s how the memory is laid out:
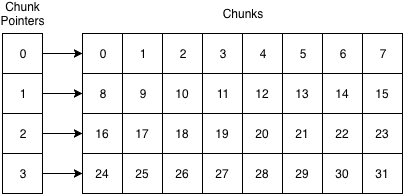
This layout allows us to traverse the list in a reasonably cache-friendly way. We’ll access sequential memory as we traverse a chunk, just like with NativeList<T> and NativeArray<T>. When we get to the end of a chunk, we might miss the CPU cache but then we’ll be accessing sequential memory again as we traverse the new chunk. The chunk pointers are also sequentially laid out in an array, so traversing them is cache-friendly too.
Random access is also easy and fast. All we need to do is compute the chunk pointer index (i / numElementsPerChunk) and then use it to index into the chunk (i % numElementsPerChunk).
Adding to a NativeChunkedList<T> is similar to NativeList<T>, but with a critical difference. If the last chunk has spare capacity, we just add the element at the end of it. If it doesn’t, we allocate a new chunk and add the element at the beginning of it. If there’s no spare capacity in the array of pointers, we allocate a new array, copy the old array over, and free the old array. This is just like the backing array of NativeList<T>, but much faster because each element is only a pointer and there are relatively few pointers since each one allows for a whole chunk of elements to be stored.
Several more operations are supported, but their implementations aren’t particularly noteworthy as nearly everything can be implemented just like with any array-backed type like NativeList<T> or even List<T>. In fact, NativeChunkedList<T> has many of the same methods and properties as NativeList<T> and List<T> so that it’s easy to use for those familiar with those types. Here’s the full API:
struct NativeChunkedList<T> : IEnumerable<T> , IEnumerable , IDisposable where T : struct { NativeChunkedList(int numElementsPerChunk, int capacity, Allocator allocator); void Add(T element) void AddRange(NativeArray<T> array, int startIndex, int length); void AddRange(T[] array, int startIndex, int length); int Capacity { get; set; } void Clear(); void CopyFrom(NativeArray<T> array, int startIndex, int length); void CopyFrom(T[] array, int startIndex, int length); void Dispose(); Enumerator GetEnumerator(); IEnumerator GetEnumerator(); IEnumerator<T> IEnumerable<T>.GetEnumerator(); void Insert(int index, T element); bool IsCreated { get; } int Length { get; } T this[int index] { get; set; } void RemoveAt(int index); void RemoveAtSwapBack(int index); T[] ToArray( T[] array = null, int startIndex = 0, int destIndex = 0, int length = -1); NativeArray<T> ToNativeArray( NativeArray<T> array = default(NativeArray<T>), int startIndex = 0, int destIndex = 0, int length = -1); }
Performance Testing
Now let’s pit NativeChunkedList<T> against NativeArray<T>, NativeList<T>, and NativeLinkedList<T> to see how it performs on a variety of operations. These tests were conducted with 10000 int elements in each collection. NativeChunkedList<T> was configured with a chunk size of 1024 bytes which equals 256 elements per chunk of int values.
The following operations were tested for each collection that supports them:
Add: Starting from an empty collection, append an element to the endIterate (Single): Iterate over the full collection in anIJobIterate (ParallelFor): Iterate over the full collection in anIJobParallelForInsert: Starting from an empty collection, insert elements into the middleRemove: Starting from a full collection, remove elements from the middle
I ran the performance tests in this environment:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.14
- Unity 2018.2.16f1
- com.unity.collections package 0.0.9-preview.10
- macOS Standalone
- .NET 4.x scripting runtime version and API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
Here are the results I got:
| Operation | Job Type | NativeArray | NativeList | NativeLinkedList | NativeChunkedList |
|---|---|---|---|---|---|
| Add | Single | n/a | 1474 | 3671 | 906 |
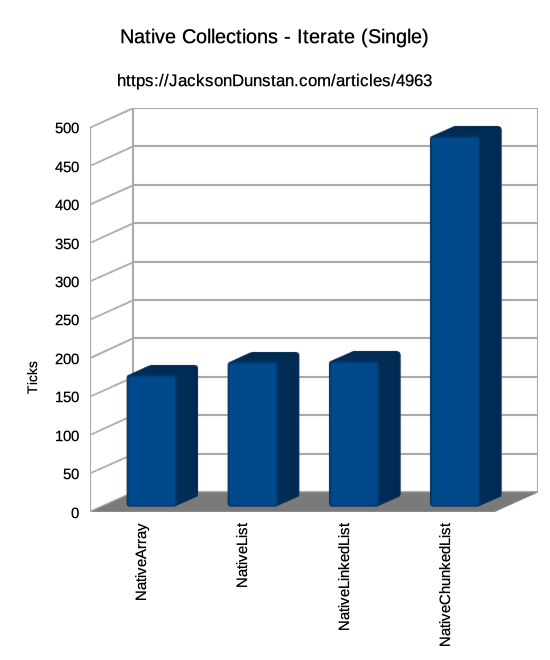
| Iterate | Single | 172 | 189 | 190 | 483 |
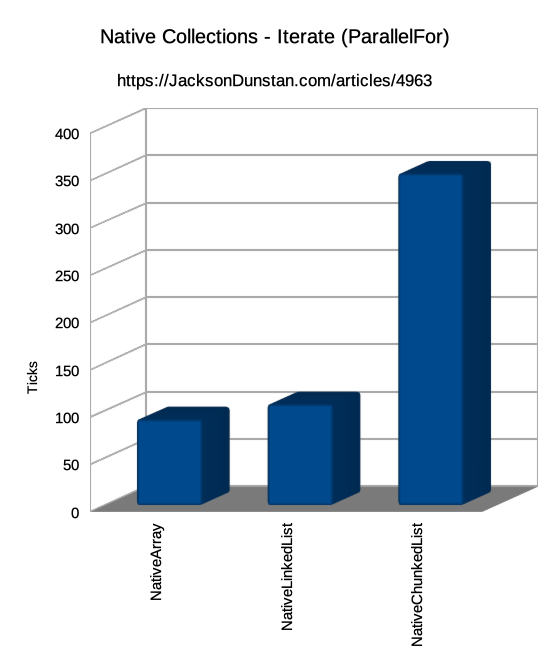
| Iterate | ParallelFor | 204 | n/a | 173 | 467 |
| Insert | Single | n/a | n/a | 904 | 1117774 |
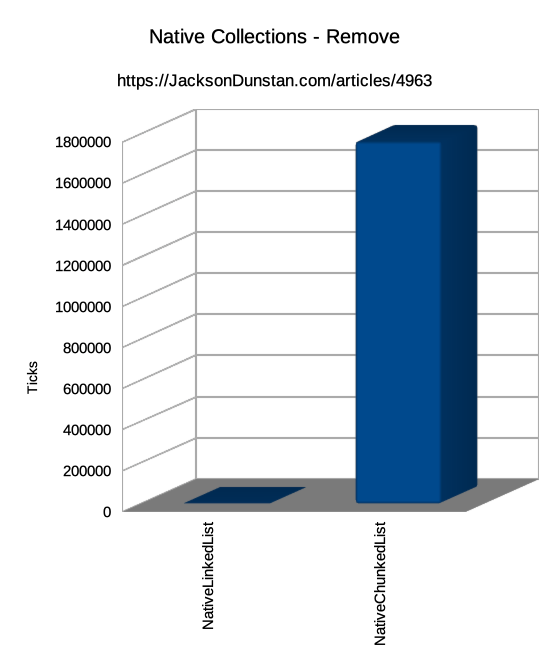
| Remove | Single | n/a | n/a | 977 | 1763470 |
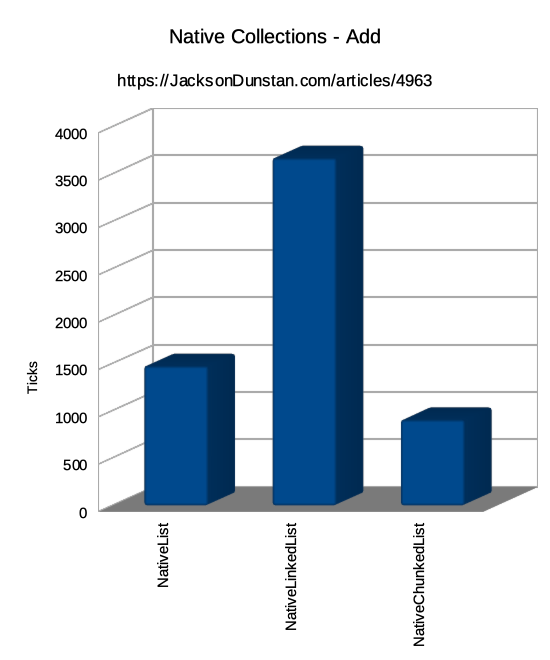
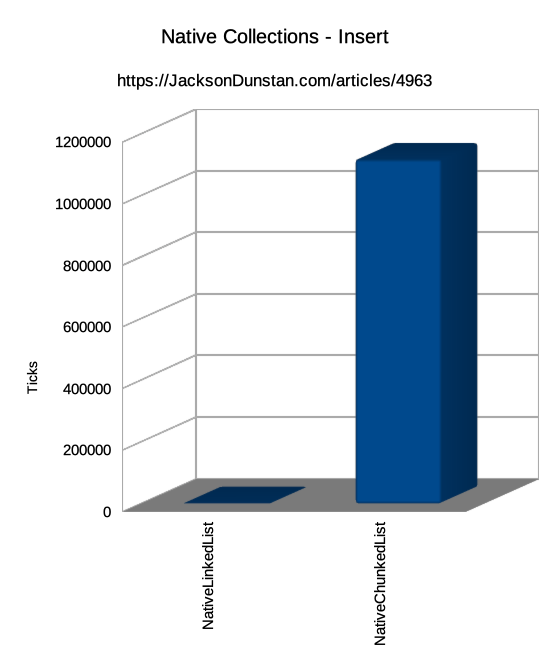
We can see here that we've succeeded in our goal to make Add faster. It takes 39% less time on average to add an element to a NativeChunkedList<T> than it does to add one to a NativeList<T> and 75% less time than NativeLinkedList<T>. This is because, unlike those other types, there are no whole-list copies when capacity runs out. For the 10000 elements in this test, NativeList<T> would have resized from a capacity of 1 then to 2 then 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192, and finally 16384. That's a lot of copies!
Iteration, either in an IJob or an IJobParallelFor, takes 2-3x more time than with the other collection types. This is due to the cache misses when going from one chunk to another, the double array indexing required by the chunks array, and the divide and modulus instructions. There's simply no way to beat the other types' single array layout. It should be noted that NativeLinkedList<T> has been pre-sorted so the nodes are sequential. If they were randomized, performance would suffer greatly and NativeChunkedList<T> would win out against it. It should also be noted that NativeChunkedList<T> is usable from an IJobParallelFor where NativeList<T> is not.
The Insert and Remove operations, only supported by NativeLinkedList<T> and NativeChunkedList<T>, shows the usual weakness of array-based data structures. These require shifting all elements after the insertion or removal point which is hugely more expensive than the linked list approach of simply fixing up the Next and Previous pointers. Also of note is that NativeList<T> and NativeChunkedList<T> feature a RemoveAtSwapBack method which avoids all the element shifting by copying the last element to the removal point. This changes the order of the array, but if order isn't important than this is far faster.
Memory Consumption
Our other goal is to reduce the waste of memory incurred by excess capacity in NativeList<T>. The final capacity of its array in the above test is 16384 which, at four bytes per int element, is 65536 bytes of memory usage. Each chunk of the NativeChunkedList<T> was 1024 bytes and held 256 elements, so there were 40 chunks when the list was full. That's 40960 bytes of memory usage for the chunks. The chunk pointers array was also present with a capacity of 64, the internal minimum. That's 256 bytes on 32-bit platforms and 512 bytes on 64-bit platforms. Let's assume 64-bit, so the total usage of the NativeChunkedList<T> was 41472. That means it saved of 24064 bytes or 37%. For larger-sized elements such as Quaternion, the gap would grow 4x wider.
In this example, the NativeChunkedList<T> was 98% full while the NativeList<T> was only 61% full. This is despite the last chunk being only 6% full, which shows how even in the worst-case scenario memory waste is kept under control. On the other hand, NativeArray<T> is sized perfectly for the data since it doesn't dynamically resize. It used 100% of its 10000 elements for a total of 40000 bytes. Compared to it, NativeChunkedList<T> used 1472 more bytes for an increase of 4%. Compared to this best-case scenario, NativeChunkedList<T> turns in a great result.
Usage
Usage of NativeChunkedList<T> is simple. It's just like using a NativeArray<T>, NativeList<T>, or NativeLinkedList<T>. Here are a few quick examples:
// Create an empty list with capacity for 4096 elements in 1024 element chunks NativeChunkedList<int> list = new NativeChunkedList<int>( 1024, 4096, Allocator.Temp); // Add some elements to the list list.Add(10); list.Add(20); list.Add(30); list.Add(40); list.Add(50); // Iterate over the list foreach (int val in list) { Debug.Log(val); } // Remove an element from the middle list.RemoveAt(2); // Insert an element into the middle list.Insert(1, 15); // Access the elements sequentially for (int i = 0; i < list.Length; ++i) { Debug.Log(list[i]); } // Dispose the list's native memory list.Dispose();
Conclusion
With NativeChunkedList<T>, we've achieved the two goals we set forth at the outset. We've got faster calls to Add with a 39% time reduction. We've also got a 37% reduction in memory usage that's now only 4% over the theoretical lowest value. While not explicit goals, we even got a pretty good suite of functionality including support for IJobParallelFor. To use the type in your own projects, check out the source code, or run the performance or unit tests, check out the NativeCollection GitHub project.
#1 by Jes on November 20th, 2018 ·
Hi
Cool Idea :)
May it can be faster in iteration using chunked iteration like in last unity ECS
Get chunk one by one and fast iterate inside chunks
May be it can be done inside enumerator too :)
#2 by jackson on November 21st, 2018 ·
Hi Jes,
Iteration is definitely lacking with the current approach, as you can see from the performance test results and analysis in the article. Stay tuned for part two, which will include your suggestion for faster iteration.