NativeHashSet<T>
Unity’s Native Collections package, currently in Preview, provides a hash map but not a hash set. Today we’ll supplement NativeHashMap<TKey, TValue> with our own NativeHashSet<T> as part of the NativeCollections repo. Read on for performance results and to see how to use it!
Unity’s NativeHashMap<TKey, TValue> is meant as a replacement for Dictionary<TKey, TValue>, but we often don’t have a value we want to map. In those times, we’d normally turn to HashSet<T> because it offers the same O(1) adding, removing, and contains checks without the need to map to any kind of value. Unfortunately, there isn’t a native version available from Unity. Enter NativeHashSet<T>.
Since we can think of NativeHashSet<T> as being a NativeHashMap<TKey, TValue> without the values, it makes sense to start with NativeHashMap<TKey, TValue> and then remove everything to do with values. So we’ll start with the current version (0.0.9-preview.12) of Unity’s Collections package and start stripping out the values. We’ll also add some things to make it fit into the NativeCollections repo better:
- Thorough xml-doc commenting
- Unit tests of every function
-
Consistent source code formatting with the other types (e.g.
NativeLinkedList<T>) - Containing the type to a single file so it can be taken a la carte
-
Performance test jobs and reports
This is a rather straightforward process, so we’ll skip the details. To really dive into them and see everything about how this works, here are some links to the project:
- Implementation
- Unit tests
- Performance tests
Now let’s see how to use NativeHashSet<T> by looking at some examples. Say you want to be able to quickly check if a player has joined the multiplayer game. In that case you can make a NativeHashSet<int> to hold the IDs of players that have joined:
// Keeps track of the IDs of players that have joined the game // Assume the game allows for up to 100 players // Setting the initial capacity to 100 means we'll never have to grow the set NativeHashSet<int> joinedPlayerIds = new NativeHashSet<int>(100, Allocator.Persistent); // When a player joins void OnPlayerJoined(Player player) { // Add their ID to the set // If it's already added, nothing happens and false is returned joinedPlayerIds.TryAdd(player.Id); } // When it's time to check if a player has joined bool HasPlayerJoined(Player player) { // Contains(int) returns whether the ID is in the set return joinedPlayerIds.Contains(player.Id); } // When a player leaves void OnPlayerLeft(Player player) { // Remove their ID from the set // If it's not in the set, nothing happens and false is returned joinedPlayerIds.Remove(player.Id); }
All of these are O(1) operations and the set will automatically grow if we exceed the initial capacity of 100.
In advanced usage, we can even add to the set from multiple threads. An easy way to do this is to use an IJobParallelFor:
struct AddPlayerIds : IJobParallelFor { [ReadOnly] public NativeArray<int> PlayerIdArray; [WriteOnly] public NativeHashSet<int>.ParallelWriter PlayerIdSetWriter; public void Execute(int index) { PlayerIdSetWriter.TryAdd(PlayerIdArray[index]); } } void AddAllPlayerIds(NativeArray<int> array, NativeHashSet<int> set) { // Get a writer that can write to the set from multiple threads at once NativeHashSet<int>.ParallelWriter writer = set.AsParallelWriter(); // Create the job to copy the array to the set AddPlayerIds job = new AddPlayerIds { PlayerIdArray = array, PlayerIdSetWriter = writer }; // Schedule the job to run on 64-element chunks of the array JobHandle handle = job.Schedule(array.Length, 64); // Wait for the job threads to complete handle.Complete(); }
Now let’s see how the type performs by running the NativeCollections repo performance tests. Here’s the test machine I ran them on:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.14.6
- Unity 2018.4.3f1
- macOS Standalone
- .NET 4.x scripting runtime version and API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
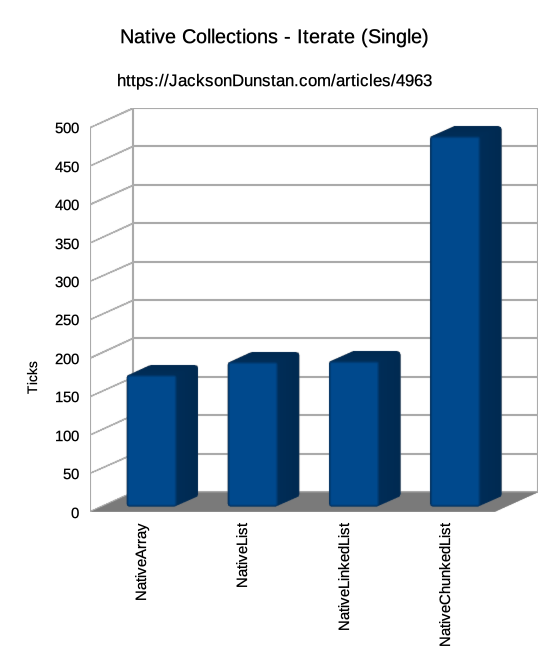
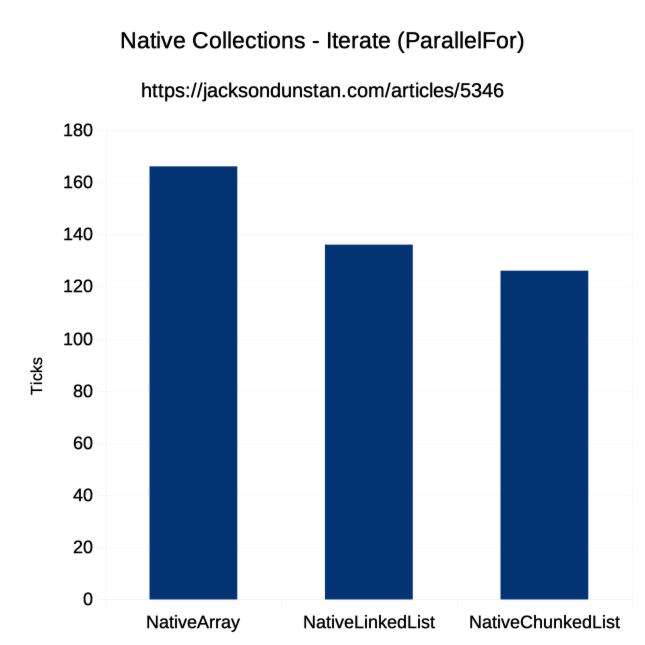
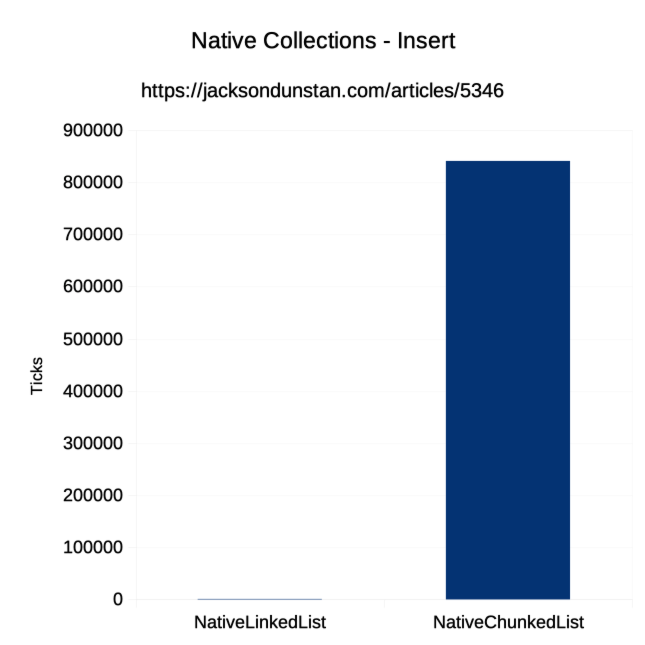
| Operation | Job Type | NativeArray | NativeList | NativeLinkedList | NativeChunkedList | NativeHashSet |
|---|---|---|---|---|---|---|
| Add | Single | n/a | 965 | 3167 | 767 | 3680 |
| Iterate | Single | 117 | 143 | 131 | 128 | n/a |
| Iterate | ParallelFor | 166 | n/a | 136 | 126 | n/a |
| Insert | Single | n/a | n/a | 969 | 840383 | n/a |
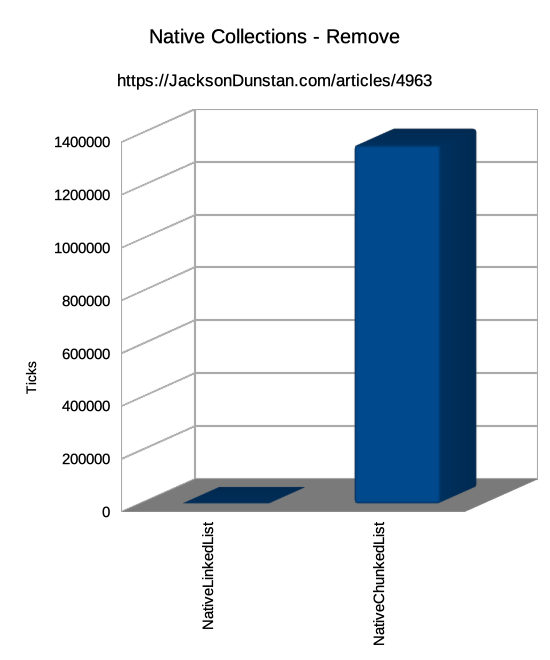
| Remove | Single | n/a | n/a | 699 | 1438269 | 245945 |
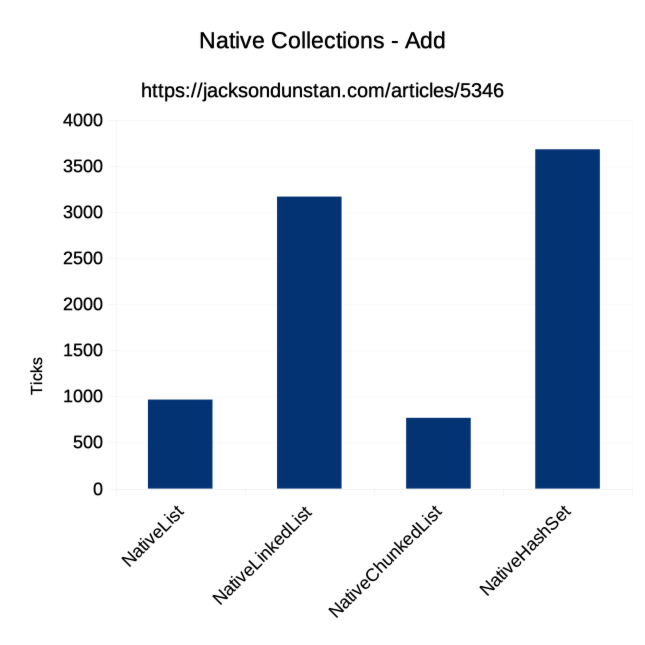
Add performance is similar to the worst-in-class NativeLinkedList<T>. It’s roughly 3-5x slower than NativeList<T> and NativeChunkedList<T>. That said, it’s at least possible unlike with the fixed-size NativeArray<T>. Adding from multiple threads could help, but it’s tough to match the cache-friendly performance of filling up an array with NativeList<T>, NativeLinkedList<T> (which is backed by an array), and NativeChunkedList<T>.
On the other side, the remove performance of NativeHashSet<T> is a lot (~6x) better than that of NativeChunkedList<T> but hideously slower (~352x) than NativeLinkedList<T>. This is to be expected because the remove operation of NativeLinkedList<T> is O(1) because the node can be found by index in O(1) and then the only work is to swap a couple of pointers. When the node to remove from the linked list can’t be looked up in constant time, this performance will suffer greatly as an O(N) scan may be necessary and, depending on how linearly organized the nodes are in the backing array, extremely cache-unfriendly.
In conclusion, NativeHashSet<T> should be a good addition to our toolboxes. We can pull it out when we need a Job-friendly, Burst-friendly way to quickly add, remove, and lookup elements but aren’t particularly interested in mapping them to anything or iterating over them. Check out the NativeCollections repo to get the type for Unity 2018.1+.
#1 by FLR on March 23rd, 2020 ·
Hello, Jackson.
I wanted to try out
NativeHashSet<T>and used the code from example but I get: InvalidOperationException: AddPlayerIds.PlayerIdSetWriter uses the [NativeContainer] but has no AtomicSafetyHandle embedded, this is an internal error in the container type.And
Am I getting something wrong here?
#2 by jackson on March 28th, 2020 ·
Thanks for reporting this issue! I found the cause and fixed it in this commit.
#3 by Seth Kelley on October 20th, 2023 ·
Came here wondering what the difference is between:
UnsafeHashMap and
UnsafeParallelHashMap
Rider’s AI can tell me a LOT about that, but there is so little documentation on any of this. :\