Fast Structs
Structs are great for controlling memory layout and avoiding the GC, but we can go a lot further to get even more speed out of them. Today we’ll look at a simple tweak that can dramatically speed up the code using the structs without even changing it!
Let’s start by designing a struct for a player in a game. First, we’ll use the object-oriented approach and put everything about the player in one big struct:
struct PlayerExtras { public Vector3 Position; // 3 * 4 = 12 public Vector3 Velocity; // 3 * 4 = 12 public int Health; // 4 public int MaxHealth; // 4 public int NumLives; // 4 public int Score; // 4 public int TeamId; // 4 public int LeftHandWeaponId; // 4 public int RightHandWeaponId; // 4 public int NumWins; // 4 public int NumLosses; // 4 public int MatchmakingRank; // 4 // Total: 64 }
The comments to the right of the fields indicate how many bytes each field takes up. This is 4 for all the int fields but 12 for Vector3 because it’s internally made up of 3 float fields which each take up 4 bytes.
Now let’s split off just the first four fields into their own struct. We’ll call this just the “basics” and define it like this:
struct PlayerBasics { public Vector3 Position; // 3 * 4 = 12 public Vector3 Velocity; // 3 * 4 = 12 public int Health; // 4 public int MaxHealth; // 4 // Total: 32 }
Now let’s consider some code that updates the position of the players in the game according to their velocity and some elapsed time: player.Position += player.Velocity * time. This is what we might do if the players were space ships, for example. We’ll simply loop over some arrays of them and performing this calculation and measuring the time with Stopwatch.
using System.Diagnostics; using UnityEngine; using Unity.IL2CPP.CompilerServices; struct PlayerBasics { public Vector3 Position; // 3 * 4 = 12 public Vector3 Velocity; // 3 * 4 = 12 public int Health; // 4 public int MaxHealth; // 4 // Total: 32 } struct PlayerExtras { public Vector3 Position; // 3 * 4 = 12 public Vector3 Velocity; // 3 * 4 = 12 public int Health; // 4 public int MaxHealth; // 4 public int NumLives; // 4 public int Score; // 4 public int TeamId; // 4 public int LeftHandWeaponId; // 4 public int RightHandWeaponId; // 4 public int NumWins; // 4 public int NumLosses; // 4 public int MatchmakingRank; // 4 // Total: 64 } class TestScript : MonoBehaviour { [Il2CppSetOption(Option.NullChecks, false)] [Il2CppSetOption(Option.ArrayBoundsChecks, false)] void Start() { const int count = 10000000; PlayerBasics[] basics = new PlayerBasics[count]; PlayerExtras[] extras = new PlayerExtras[count]; float time = Random.Range(0, 1); Stopwatch sw = Stopwatch.StartNew(); for (int i = 0; i < count; ++i) { ref PlayerBasics player = ref basics[i]; player.Position += player.Velocity * time; } long basicsTime = sw.ElapsedMilliseconds; sw.Reset(); sw.Start(); for (int i = 0; i < count; ++i) { ref PlayerExtras player = ref extras[i]; player.Position += player.Velocity * time; } long extrasTime = sw.ElapsedMilliseconds; print( "Type,Timen" + "Basics," + basicsTime + "n" + "Extras," + extrasTime); } }
Now let’s run this code to see how each loop performed. I ran using this environment:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.14.3
- Unity 2018.3.1f1
- macOS Standalone
- .NET 4.x scripting runtime version and API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
Here are the results I got:
| Type | Time |
|---|---|
| Basics | 41 |
| Extras | 63 |
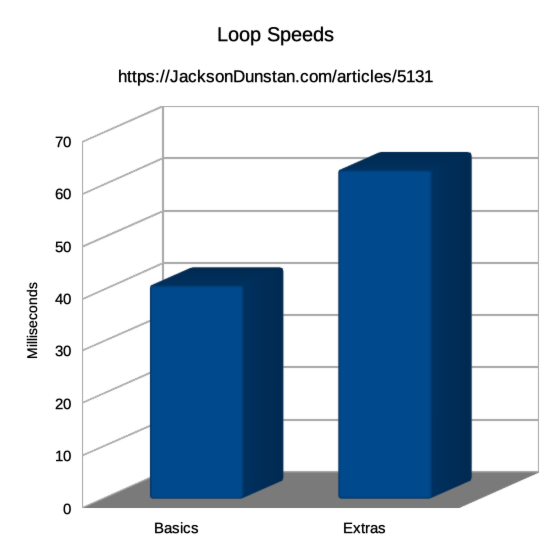
The “extras” version of the player struct makes the loop take 47% more CPU time! It’s the exact same code running on the exact same number of structs, so why is it so slow?
The answer lies in the size of the structs being iterated over. In order to perform the calculation, the code needs to read the Position and Velocity fields from memory. When it reads Position, the CPU doesn’t read just the x, y, and z floats but an entire “cache line” of 64 bytes. In the case of PlayerExtras, this means the CPU reads all the other fields of the struct that will never be used.
To illustrate, let’s assume the first PlayerExtras element of the extras array is in memory at address 100. Here’s how that memory would look:
| Address | Index | Variable |
|---|---|---|
| 100 | 0 | Position.x |
| 104 | 0 | Position.y |
| 108 | 0 | Position.z |
| 112 | 0 | Velocity.x |
| 116 | 0 | Velocity.y |
| 120 | 0 | Velocity.z |
| 124 | 0 | Health |
| 128 | 0 | MaxHealth |
| 132 | 0 | NumLives |
| 136 | 0 | Score |
| 140 | 0 | TeamId |
| 148 | 0 | LeftHandWeaponId |
| 152 | 0 | RightHandWeaponId |
| 156 | 0 | NumWins |
| 160 | 0 | NumLosses |
| 164 | 0 | MatchmakingRank |
This one struct takes up the entire cache line, so reading the next element of the array means it isn’t in cache and a new cache line needs to be fetched from RAM.
Now let’s look at PlayerBasics. Since it’s half the size, we see that two of them are fetched when the first one’s Position is read:
| Address | Index | Variable |
|---|---|---|
| 100 | 0 | Position.x |
| 104 | 0 | Position.y |
| 108 | 0 | Position.z |
| 112 | 0 | Velocity.x |
| 116 | 0 | Velocity.y |
| 120 | 0 | Velocity.z |
| 124 | 0 | Health |
| 128 | 0 | MaxHealth |
| 132 | 1 | Position.x |
| 136 | 1 | Position.y |
| 140 | 1 | Position.z |
| 148 | 1 | Velocity.x |
| 152 | 1 | Velocity.y |
| 156 | 1 | Velocity.z |
| 160 | 1 | Health |
| 164 | 1 | MaxHealth |
This means that the second element of the array can use the struct that’s already in cache rather than reaching out to RAM to fetch it.
As this page neatly shows, using the CPU cache for half of the elements of the array means we’re only waiting 1-4 nanoseconds for that memory instead of 100 nanoseconds to fetch it from RAM. That 25-100x speedup gives us a huge speed boost that makes using the “basics” version of the struct so much faster.
In general, try to keep the size of structs small if they need to be efficiently iterated over. This will improve the performance of the code even without changing it just by making more efficient use of the CPU cache.
#1 by Serg on March 20th, 2019 ·
Is it faster than iterating array of reference type?
#2 by jackson on March 20th, 2019 ·
Yes, because that would be an array of pointers to essentially random memory locations which would imply a cache miss at every iteration of the loop as well as reduced or no prefetching of memory into the cache.
#3 by Andy on January 6th, 2020 ·
Yet Microsoft & friends suggest a struct only if ‘It has an instance size under 16 bytes’!
I guess it depends on how often you loop over it vs other actions.
#4 by Noam on August 24th, 2019 ·
This is interesting. I just recently refactored some code iterates on a bunch of different stuff (steering/flocking behaviors) using code very similar to the one in Mike Acton’s talk (and some directly adapted from it). I previously had everything in its own arrays (positions, directions, etc) and now I have a whole big ‘MovementData’ struct.
I have all the processing done during the frame, then copied back and some of it handed off to indirect instancing for rendering. I figured combining it would make things faster but maybe not. But it’s hard to tell when the whole thing is already using Burst. Does this mean that iterating on (for example) just positions would actually cache 4 of them with a float4 and 5 of them with a float3? I’m not sure if it would even work the same since I’m using IJobParallelFor for most of this.
Also, I didn’t know you could use ‘ref’ on struct arrays like that. Is that faster than the copy, process, copy back approach? If so, that’s more stuff I can improve on!
#5 by jackson on August 24th, 2019 ·
It’s true that you’ll fit more
float3vectors in a cache line than withfloat4, so you’ll get a performance boost on the memory side. However, Burst will generate better SIMD machine code withfloat4than withfloat3, so you’ll be losing out on a performance boost on the CPU side. It’s important to know where you’re bound: on memory or on the CPU. That can help guide your decision about which type to use. If it’s easy to switch between them, you can also just profile both approaches and see which is faster on your target hardware.As for local
refvariables, that was added in newer versions of C#. It avoids telling the compiler to copy every element of the struct to a temporary variable and then copying it back. Instead, you just operate on the data in place. The actual performance is highly dependent on Boost’s optimizations, so check the Burst Inspector to see what machine code is generated with both approaches and profile on your target hardware to confirm.Have fun with Burst, jobs, and “high performance C#”!
#6 by Noam on August 26th, 2019 ·
Thanks for the response! I did see a mention somewhere about the float4 being the more optimized of the two. I do use those already at least in part, since some of my data previously comes from a BoundingSphere.
As for the Burst inspector, I’m afraid I don’t know any assembly, nor enough C++ to really get the output there. As for my target hardware… for this project that’s PCs, consoles, and Apple mobile devices, but we’ve got a partner thankfully who’s doing most of the porting work.
Aside from that, I already am enjoying Burst, jobs, and hpc#! I’ve got 50k+ fish reliably, I’m just blocked by some data copy times and a bug with my gpu sorting that breaks after exactly 65k instances :) (Though I’ve had over 200k in a build at one point before I added some other stuff!)
Side note, is there a way to get notified for replies? I don’t know exactly how many other posts I’ll be commenting on, but I didn’t realize there’s no notification, I’ll have to keep track when I do, otherwise.
#7 by jackson on August 26th, 2019 ·
That’s a lot of fish! :-D
WordPress doesn’t send e-mails for comment replies, but you can subscribe to an RSS feed of all the comments on the article if you want.
#8 by Noam on August 26th, 2019 ·
That works, thanks!
#9 by Nitzan on April 17th, 2024 ·
Why not use a Data Oriented approach and create a single class to hold arrays for all our enemy data?
public class EnemyData
{
public Vector3[] Position;
public Vector3[] Direction;
public float[] HP;
public int[] Score;
// etc…
}
Then you can loop over the arrays:
for(int i = 0; i < numEnemies; i++)
{
EnemyData.Position[i] += EnemyData.Direction[i];
}
This will ensure the cache line includes the maximum amount of relevant data.
Even better, you won't have to create a bunch of small structs to hold everything. Plus you just know the game design is going to one day ask for data from different structs, which will make you load multiple small structs which will absolutely destroy the cache line.
#10 by Nitzan on April 17th, 2024 ·
Why not use a Data Oriented approach and create a single class to hold arrays for all our enemy data?
public class EnemyData
{
public Vector3[] Position;
public Vector3[] Direction;
public float[] HP;
public int[] Score;
// etc…
}
Then you can loop over the arrays:
for(int i = 0; i < numEnemies; i++)
{
EnemyData.Position[i] += EnemyData.Direction[i];
}
This will ensure the cache line includes the maximum amount of relevant data.
Even better, you won't have to create a bunch of small structs to hold everything. Plus you just know the game design is going to one day ask for data from different structs, which will make you load multiple small structs which will absolutely destroy the cache line.