Problem and Solution: The Terrible Inefficiency of FileStream and BinaryReader
File I/O can be a major performance bottleneck for many apps. It’s all too easy to read files in a way that is massively inefficient. Classes like FileStream and BinaryReader make it really easy to write super slow code. Today’s article explores why this happens and what can be done about it. Read on to learn more!
Say you want to read a 10 megabyte file containing a huge series of unsigned 2-byte values: ushort. How do you read this file? The typical approach would involve a FileStream and a BinaryReader like this:
// Open the file using (var stream = new FileStream("/path/to/file", FileMode.Open)) { // Compute how many values the file has var numValues = stream.Length / sizeof(ushort); // Allocate an array to hold all those values var readValues = new ushort[numValues]; // Open a reader to make reading those values easy using (var reader = new BinaryReader(stream)) { // Read all the values for (var i = 0; i < numValues; ++i) { readValues[i] = reader.ReadUInt16(); } } }
On my test system (described later), this takes about 272 milliseconds! That’s definitely long enough that you’ll need to spread the load out over multiple frames of the game in order to keep a smooth frame rate. Maybe you’ll use another thread to handle the task. Regardless, your code is about to get a lot more complex, error-prone, and difficult to manage. Not to mention the user is going to have to wait longer for the file to get loaded.
But what if we could load the file faster? We know it’s important to minimize the number of read() calls made to the OS and FileStream does that for us. It has an internal buffer that defaults to a perfectly-reasonable 4 kilobytes in size. So when you read the first two bytes of the file it actually reads 4 kilobytes. The second read just takes two bytes out of the buffer and doesn’t make any read() calls to the OS. Great!
With this in mind we can plot the performance of different size reads from FileStream using its Read function:
var numBytesRead = myFileStream.Read(myBuffer, offsetIntoMyBuffer, numBytesToRead);
Here’s what happens when I run that test on the same test system as above:
| Read Size | Time |
|---|---|
| 2 | 227 |
| 4 | 118 |
| 8 | 58 |
| 16 | 31 |
| 32 | 17 |
| 64 | 10 |
| 128 | 6 |
| 256 | 4 |
| 512 | 3 |
| 1024 | 3 |
| 2048 | 3 |
| 4096 | 3 |
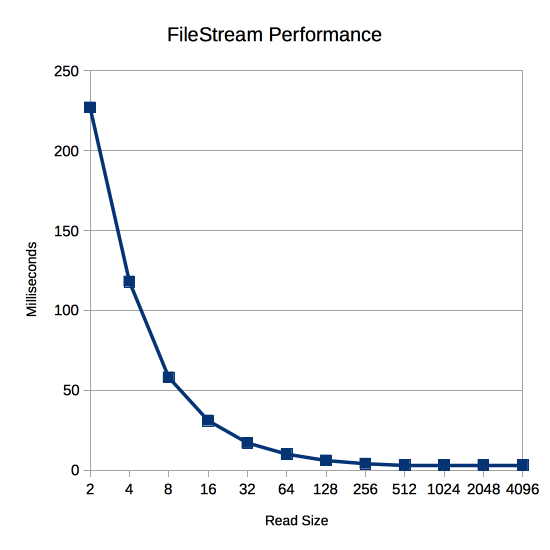
The read size makes a huge difference! Just reading 4096 bytes at a time instead of 2 bytes at a time is 75x faster! But why is this the case? Isn’t FileStream just copying from its internal buffer? Isn’t that way faster than reading from the file system?
The answer lies in the CPU performance of FileStream, not the disk I/O performance. To find out why it’s so slow, let’s decompile the mscorlib.dll that comes with Unity 5.4’s version of Mono and see how FileStream is implemented. First, here’s the Read we call from our app:
public override int Read([In] [Out] byte[] array, int offset, int count) { if (this.handle == MonoIO.InvalidHandle) { throw new ObjectDisposedException("Stream has been closed"); } if (array == null) { throw new ArgumentNullException("array"); } if (!this.CanRead) { throw new NotSupportedException("Stream does not support reading"); } int num = array.Length; if (offset < 0) { throw new ArgumentOutOfRangeException("offset", "< 0"); } if (count < 0) { throw new ArgumentOutOfRangeException("count", "< 0"); } if (offset > num) { throw new ArgumentException("destination offset is beyond array size"); } if (offset > num - count) { throw new ArgumentException("Reading would overrun buffer"); } if (this.async) { IAsyncResult asyncResult = this.BeginRead(array, offset, count, null, null); return this.EndRead(asyncResult); } return this.ReadInternal(array, offset, count); }
Whoa! 8 if statements right off the bat! Those can be quite slow because the CPU doesn’t know which code—the if or the else—is going to get executed, so it breaks its ability to predict and slows the code down. Notice that they’re mostly sanity checks, too. Is the stream open? Did you pass a null array? Can you read from this stream? Are your offset and count non-negative? The odds are extremely high that you’re not making any of these mistakes, but you’re going to pay for them 5,242,880 times over the course of a 10 megabyte file!
Next let’s look at the ReadInternal call at the end of Read:
private int ReadInternal(byte[] dest, int offset, int count) { int num = 0; int num2 = this.ReadSegment(dest, offset, count); num += num2; count -= num2; if (count == 0) { return num; } if (count > this.buf_size) { this.FlushBuffer(); num2 = this.ReadData(this.handle, dest, offset + num, count); this.buf_start += (long)num2; } else { this.RefillBuffer(); num2 = this.ReadSegment(dest, offset + num, count); } return num + num2; }
Here we’ve got one or two more if statements for a total of 9-10 so far across three function calls (FileStream.Read, Stream.Count, FileStream.ReadInternal). Right away this function calls into another function: ReadSegment
private int ReadSegment(byte[] dest, int dest_offset, int count) { if (count > this.buf_length - this.buf_offset) { count = this.buf_length - this.buf_offset; } if (count > 0) { Buffer.BlockCopy(this.buf, this.buf_offset, dest, dest_offset, count); this.buf_offset += count; } return count; }
Two more if statements for a total of 11-12 and 4 function calls. Here’s Buffer.BlockCopy:
public static void BlockCopy(Array src, int srcOffset, Array dst, int dstOffset, int count) { if (src == null) { throw new ArgumentNullException("src"); } if (dst == null) { throw new ArgumentNullException("dst"); } if (srcOffset < 0) { throw new ArgumentOutOfRangeException("srcOffset", Locale.GetText("Non-negative number required.")); } if (dstOffset < 0) { throw new ArgumentOutOfRangeException("dstOffset", Locale.GetText("Non-negative number required.")); } if (count < 0) { throw new ArgumentOutOfRangeException("count", Locale.GetText("Non-negative number required.")); } if (!Buffer.BlockCopyInternal(src, srcOffset, dst, dstOffset, count) && (srcOffset > Buffer.ByteLength(src) - count || dstOffset > Buffer.ByteLength(dst) - count)) { throw new ArgumentException(Locale.GetText("Offset and length were out of bounds for the array or count is greater than the number of elements from index to the end of the source collection.")); } }
Six more if statements and we’re up to 17-18 and 5 function calls. Many of these checks are redundant with checks that have already been performed. At the end this calls Buffer.BlockCopyInternal and Buffer.ByteLength:
[MethodImpl(MethodImplOptions.InternalCall)] internal static extern bool BlockCopyInternal(Array src, int src_offset, Array dest, int dest_offset, int count); public static int ByteLength(Array array) { if (array == null) { throw new ArgumentNullException("array"); } int num = Buffer.ByteLengthInternal(array); if (num < 0) { throw new ArgumentException(Locale.GetText("Object must be an array of primitives.")); } return num; } [MethodImpl(MethodImplOptions.InternalCall)] private static extern int ByteLengthInternal(Array array);
That’s three more function calls for a total of 8, two of which are in native C code. ByteLength does some more redundant if checking to bring the count up to 19-20.
After that in ReadInternal we’re just dealing with the cases where data needs to actually be read from the file system. If we’re reading 2 bytes at a time with a 4096 byte buffer, that’s an extreme minority of calls. Feel free to look through the code with a decompiler if you want, but I’ll skip it for the purposes of this article.
Now that we’ve seen that a call to FileStream.Read results in 8 function calls and 19-20 if statements just to read two bytes, let’s look and see what additional overhead is incurred by using BinaryReader. Here are the functions involved in calling its ReadUInt16:
[CLSCompliant(false)] public virtual ushort ReadUInt16() { this.FillBuffer(2); return (ushort)((int)this.m_buffer[0] | (int)this.m_buffer[1] << 8); } protected virtual void FillBuffer(int numBytes) { if (this.m_disposed) { throw new ObjectDisposedException("BinaryReader", "Cannot read from a closed BinaryReader."); } if (this.m_stream == null) { throw new IOException("Stream is invalid"); } this.CheckBuffer(numBytes); int num; for (int i = 0; i < numBytes; i += num) { num = this.m_stream.Read(this.m_buffer, i, numBytes - i); if (num == 0) { throw new EndOfStreamException(); } } } private void CheckBuffer(int length) { if (this.m_buffer.Length <= length) { byte[] array = new byte[length]; Buffer.BlockCopyInternal(this.m_buffer, 0, array, 0, this.m_buffer.Length); this.m_buffer = array; } }
This brings the total up to 11 function calls and 23-24 if statements. BinaryReader didn’t add too much, but the overall process is super wasteful leading to the awful performance graph above.
So how can we optimize this? The goal must surely be to minimize calls to FileStream.Read. The BinaryReader class will call it every single time we want to read two bytes, so we can’t use that. It’s a shame since functions like ReadUInt16 are so useful for reading formatted data and not just blocks of bytes.
There’s nothing stopping us from writing our own BufferedBinaryReader though. The goal is to keep a buffer inside BufferedBinaryReader with the same size as the one in the FileStream. Then we can call Read just once to fill our buffer and only incur all those function calls and if statements every 2048 times we read a ushort with a 4 kilobyte buffer. For the other 2047 times we can just assume that the user knows what they’re doing and skip all the checks. After all, they’ll just get an IndexOutOfRangeException instead of the various exception types in FileStream and BinaryReader, so it’s hardly any less safe.
Lastly, we provide some functionality to control the buffer. This comes in the form of an explicit FillBuffer function that uses the FileStream to refill its buffer and a NumBytesAvailable property to check how many bytes have been buffered and are ready for reading.
To use BufferedBinaryReader we write a very simple loop:
// Allocate an array to hold all the values var numValues = FileSize / sizeof(ushort); var readValues = new ushort[numValues]; // Keep reading while there's more data while (bufferedReader.FillBuffer()) { // Read as many values as we can from the reader's buffer var readValsIndex = 0; for ( var numReads = bufferedReader.NumBytesAvailable / sizeof(ushort); numReads > 0; --numReads ) { readValues[readValsIndex++] = bufferedReader.ReadUInt16(); } }
The BufferedBinaryReader.ReadUInt16 just looks like this:
public ushort ReadUInt16() { var val = (ushort)((int)buffer[bufferOffset] | (int)buffer[bufferOffset+1] << 8); bufferOffset += 2; return val; }
The full source code for BufferedBinaryReader is in the following test script. It’s very basic as it only has the ability to read ushort values, but feel free to port the rest of the ReadX functions from mscorlib.dll if you’d like.
Now let’s put BufferedBinaryReader to the test against BinaryReader. The following test script has the test code for that as well as the performance chart above.
using System; using System.IO; using UnityEngine; public class BufferedBinaryReader : IDisposable { private readonly Stream stream; private readonly byte[] buffer; private readonly int bufferSize; private int bufferOffset; private int numBufferedBytes; public BufferedBinaryReader(Stream stream, int bufferSize) { this.stream = stream; this.bufferSize = bufferSize; buffer = new byte[bufferSize]; bufferOffset = bufferSize; } public int NumBytesAvailable { get { return Math.Max(0, numBufferedBytes - bufferOffset); } } public bool FillBuffer() { var numBytesUnread = bufferSize - bufferOffset; var numBytesToRead = bufferSize - numBytesUnread; bufferOffset = 0; numBufferedBytes = numBytesUnread; if (numBytesUnread > 0) { Buffer.BlockCopy(buffer, numBytesToRead, buffer, 0, numBytesUnread); } while (numBytesToRead > 0) { var numBytesRead = stream.Read(buffer, numBytesUnread, numBytesToRead); if (numBytesRead == 0) { return false; } numBufferedBytes += numBytesRead; numBytesToRead -= numBytesRead; numBytesUnread += numBytesRead; } return true; } public ushort ReadUInt16() { var val = (ushort)((int)buffer[bufferOffset] | (int)buffer[bufferOffset+1] << 8); bufferOffset += 2; return val; } public void Dispose() { stream.Close(); } } public class TestScript : MonoBehaviour { private const int FileSize = 10 * 1024 * 1024; void Start() { var path = Path.Combine(Application.persistentDataPath, "bigfile.dat"); try { File.WriteAllBytes(path, new byte[FileSize]); TestFileStream(path); TestBinaryReaders(path); } finally { File.Delete(path); } } private void TestFileStream(string path) { using (var stream = new FileStream(path, FileMode.Open)) { var stopwatch = System.Diagnostics.Stopwatch.StartNew(); var readBytes = new byte[FileSize]; var log = "Read Size,Time\n"; foreach (var readSize in new[]{ 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096 }) { stream.Position = 0; stopwatch.Reset(); stopwatch.Start(); var offset = 0; do { offset += stream.Read(readBytes, offset, Math.Min(readSize, FileSize - offset)); } while (offset < FileSize); var time = stopwatch.ElapsedMilliseconds; log += readSize + "," + time + "\n"; } Debug.Log(log); } } private void TestBinaryReaders(string path) { using (var stream = new FileStream(path, FileMode.Open)) { var stopwatch = System.Diagnostics.Stopwatch.StartNew(); var log = "Reader,Time\n"; var numValues = FileSize / sizeof(ushort); var readValues = new ushort[numValues]; var reader = new BinaryReader(stream); stopwatch.Reset(); stopwatch.Start(); for (var i = 0; i < numValues; ++i) { readValues[i] = reader.ReadUInt16(); } var time = stopwatch.ElapsedMilliseconds; log += "BinaryReader," + time + "\n"; stream.Position = 0; var bufferedReader = new BufferedBinaryReader(stream, 4096); stopwatch.Reset(); stopwatch.Start(); while (bufferedReader.FillBuffer()) { var readValsIndex = 0; for ( var numReads = bufferedReader.NumBytesAvailable / sizeof(ushort); numReads > 0; --numReads ) { readValues[readValsIndex++] = bufferedReader.ReadUInt16(); } } time = stopwatch.ElapsedMilliseconds; log += "BufferedBinaryReader," + time + "\n"; Debug.Log(log); } } }
If you want to try out the test yourself, simply paste the above code into a TestScript.cs file in your Unity project’s Assets directory and attach it to the main camera game object in a new, empty project. Then build in non-development mode for 64-bit processors and run it windowed at 640×480 with fastest graphics. I ran it that way on this machine:
- 2.3 Ghz Intel Core i7-3615QM
- Mac OS X 10.11.5
- Apple SSD SM256E, HFS+ format
- Unity 5.4.0f3, Mac OS X Standalone, x86_64, non-development
- 640×480, Fastest, Windowed
And here are the results I got:
| Reader | Time |
|---|---|
| BinaryReader | 272 |
| BufferedBinaryReader | 24 |
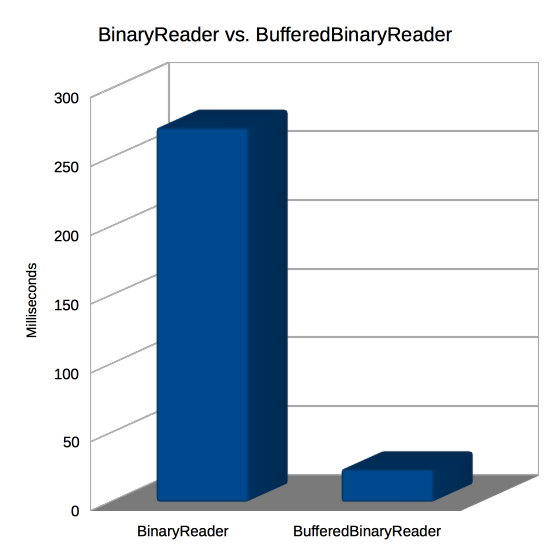
This shows that BufferedBinaryReader is about 11x faster than regular BinaryReader! That shouldn’t be much of a surprise since the performance test above showed similar times for 2 byte reads (272 here, 227 there) versus 4096 byte reads (24 here, 3 there). Remember the discussion of spreading the file loading out over multiple frames and maybe reading it from another thread? At only 24 milliseconds for a 10 megabyte file, that’s probably not going to be necessary if you have a more reasonable file size like 1 megabyte. Your code can be a lot simpler and the user can have their data immediately!
In conclusion, FileStream has a lot of CPU overhead for every call to its Read function regardless of the internal buffering its doing for calls to the OS’ native read function. To speed up your reads from disk, read as much as you can into your own buffer to minimize the FileStream overhead. A class like BufferedBinaryReader can make this pretty painless and massively speed up your performance.
If you’ve got any questions or tips you’d like to share about file I/O performance in Unity, please drop me a line in the comments!
#1 by Simon on September 5th, 2016 ·
What would be interesting is how File.ReadAllBytes() performs in comparison to this. In many scenarios it would be ok to keep all bytes in memory until the file is fully processed I guess
#2 by jackson on September 5th, 2016 ·
Here’s what
File.ReadAllByteslooks like when decompiled:Since the read size (
i) is always the whole remaining file, it’s almost always going to be really large. I did a quick test using the same computer as in the article and it performs about as well as the 4096 byte read size.The downside, of course, is that you still have to deal with a raw byte array rather than formatted values like
ushort. You could wrap that byte array in aMemoryStreamand aBinaryReader, but you’ll suffer similar problems with those as described in the article. I took a quick look atMemoryStream.Readand it costs 12ifs, 2 C# function calls, and 2 native function calls. Cheaper thanFileStream.Read, but still really expensive!#3 by Mariana Barros on June 28th, 2017 ·
Hello thank you for this! I am trying to apply it to my code, but I am kind of a beginner and I am trying to use this to open a text file and I tried to use .ReadString() instead of .ReadUInt16(), like you said we could port any ReadX function, but unity doesn’t recognize some of the specific code the .ReadString() function requires.
Would you consider giving an exemple as to transform an text file into a big string with this save timing method?
I am in this for some days now, and starting to feel desperate…
thank you in advance!
Mariana Barros
#4 by jackson on June 28th, 2017 ·
Hey Mariana,
There actually isn’t much point to using this if you just need to read a whole text file in as a string. The simple
File.ReadAllTextfunction is fine for that. The technique and code shown in this article is more for when you need to read a file a bit at a time. For example, if you were parsing a custom data format.File.ReadAllTextwill read the entire file in one call, so your performance should be as good as possible.Hope that helps,
-Jackson
#5 by Dave O'Dwyer on August 8th, 2017 ·
Thanks for your very well written article above. I was hoping it would solve my issue but unfortunately i seem to have a different problem as i am already reading bytes in large chunks.
I have a unity package reading 20’736 bytes from a binary file evey 100ms. I am using “buffer = binaryReader.ReadBytes(20736)â€
If I take a timing on this I can see that roughly every 40 good reads done, there begins a ‘bad patch’ of 40 reads where the timings spike up to as much as 276ms to perform the read. This pattern repeats consistently with the eratic pattern the bad spikes make looking much the same each time.
Any ideas would be appreciated. Thanks.
#6 by jackson on August 8th, 2017 ·
byte[] BinaryReader.ReadBytes(int count)returns a newly-allocatedbyte[]each time you call it. That means you’re creating about 20 KB of garbage for the GC to collect every 100 ms. Try switching toint BinaryReader.Read(byte[] buffer, int index, int count)which will read into abyte[]that you provide instead of allocating a new one. That way you can reuse the same buffer of 20736 bytes and never release it to the GC.Also keep in mind that the main purpose of
BinaryReaderis to help you read formatted data like various sizes of integers, strings, etc. If you just need to read abyte[], you might want to skip theBinaryReaderand its (expensive) internal buffering in favor of using aFileStreamdirectly. It has the sameint FileStream.Read(byte[] buffer, int index, int count)function, so it’s just as easy to use.Hope that helps!
#7 by Vadim on June 11th, 2018 ·
Very nice observation here, thank you!
Could you please clarify how the code you published in this post is licensed?
#8 by jackson on June 11th, 2018 ·
I’m glad you enjoyed the post! The code in this post, and every other post so far, is under the MIT license.
#9 by travis on September 12th, 2018 ·
Hi, I cant see how to get the Byte[] out of the BufferedBinaryReader.
Can you tell me how to set a Byte[] from a stream using this?
#10 by jackson on September 12th, 2018 ·
There’s no way to do that as it’s written in the article, but feel free to add a getter or just make it
publicin your own copy. Just keep in mind that the buffer’s contents will vary based on the I/O reads thatBufferedBinaryReaderperforms.#11 by Tom on October 17th, 2018 ·
I was wondering how a float value could be read in stead of a uint
#12 by jackson on October 17th, 2018 ·
You’ll need to read four bytes as a
uintthen reinterpret theuintafloat. Here’s anunsafeversion:#13 by Lambert Wolterbeek Muller on January 19th, 2019 ·
hi Jackson,
Thanks for your article & analysis. I guess my homework is to write a little tool that uses reflection to generate the code to efficiently read my class with 24 members of various native types :)
Thanks again for the research & info !
Lambert
#14 by Lambert again on January 19th, 2019 ·
Wait.. could the information in this article be outdated?
This “reference source” for
BinaryReader.ReadInt64looks pretty efficient?https://referencesource.microsoft.com/#q=BinaryReader.ReadInt64
#15 by jackson on January 20th, 2019 ·
Microsoft’s reference source for BinaryReader.Read definitely looks different than in the article, but it’s important to remember that Unity isn’t necessarily using that exact source.
Here’s what I do to look at what Unity is using. First, build the Unity project. Second, decompile
/path/to/project/Library/PlayerDataCache/PLATFORM/Data/Managed/mscorlib.dll. ChangePLATFORMto iOS or whatever platform you built for. Changemscorlib.dllto whatever .NET library you’re interested in. There are several good decompilers available including ILSpy and dotPeek. Finally, open upSystem.IO/BinaryReader.csand peruse the code.In this case, the code has changed in the years since I wrote this article. I won’t go in depth here, but
Readnow looks like this in my Unity 2018.3.1f1 iOS build:It’s no longer using the internal buffer of the
BinaryReaderand is now “just” an overhead of fiveifbranches before it callsStream.Readwith the same parameters. If you don’t need the error-checking, just callreader.BaseStream.Read(buffer, index, count)to skip those branches.#16 by jackson on January 20th, 2019 ·
If you’re willing to enable “unsafe” code then you can directly cast the memory rather than generating code to read one field at a time. For example:
#17 by MGK on May 3rd, 2019 ·
Hi Jackson, I’ve been researching binary write and read today and I stumbled into your article. I know this article is a few years old, but I need to read a binary file I totally control as quickly as possible and my initial attempts using a BinaryReader just aren’t fast enough. I am creating a dictionary of int32 as key and array of int32 as value. I split this large index file (it’s used to map a large array to it’s parent via index or position for blazing fast searches in a primary app) into partitioned files and stream them in via async tasks from S3. I initially was just using message pack serialization and LZ4 compression, but it just wasn’t fast enough. So, I decided to try just straight binary reads since I can format the data myself and I know that format. I’m interested in this unsafe approach, but I’m not sure how to approach it for a dictionary or key value pair. I am currently writing the binary file as Int32 as key, Count of Values, each value, repeat so I know how it materializes back when doing the deserialization. My average file size is about 20 megs. I’m curious if you would take an unsafe approach to this, a different one, or if your bufferedbinaryreader is still the way to go.
#18 by jackson on May 4th, 2019 ·
It sounds like there are three parts to your problem. First there’s the reading of the file itself. Second there’s the parsing of the file into a usable form. Third there’s the using of the parsed data. You can make tradeoffs between these three parts depending on the hardware you expect to run on. For example, if reading from disk is much slower than CPU then you might want to read a compressed file (e.g. you mentioned LZ4) to make the first part faster at the cost of the second part. Or you might avoid parsing during the second part by doing more parsing in the third part.
An approach like
BinaryReaderorBufferedBinaryReadercombines the first two parts because it both reads from disk and parses into usable data. To make the first part as fast as possible, skip both of these classes and go straight to a single call toFileStream.Readthat reads the whole file. That whole file may be compressed or not depending on your expected read I/O performance. Then proceed to parse the loaded data with code that knows the specific format of the file, not just generalizations such as a 32-bit integer. You can hand-optimize that code to maximize its performance and make trade-offs between the second and third parts.#19 by MGK on May 5th, 2019 ·
Hi Jackson, thanks for the feedback. I like your take on this. If you don’t mind me asking, do you have a brief air code example of “skipping the first part” and using Filestream.Read and then since I know the format, “skip the generalizations and int32”? I believe I’ve started down this route, in that I take the result of the S3 response and use .CopyTo() to move that stream to a memorystream and then get the bytes via ToArray(). This is now by far the slowest part. Then, once I have the bytes I pass this into Buffer.BlockCopy and populate an array of int since that is all I have in the end. That part seems to be fast, but perhaps not as fast as *possible*. I’m not sure if the CopyTo is a double hop or if you would approach it differently.
#20 by jackson on May 5th, 2019 ·
Sure thing. For
FileStream.Read, you’d do something like this:Essentially you’re just reading the whole file at once rather than in little pieces. This tends to maximize I/O performance. However, it sounds like you might actually not be reading from a file since you mention S3 which I presume is a download from Amazon S3. In that case
FileStreamdoesn’t apply. If that’s the case, try to keep to raw arrays rather than wrappers likeMemoryStreamas they can add quite a lot of overhead with all their virtual functions and error-checking.For “skipping the generalizations,” I mean that the “Use buffer” part of the above can be custom code specific to your file format. So there’s no need to restrict yourself to basic types like 32-bit integers. For example, you could use variable-length or 3-byte integers if you wanted to. You can also use
fixedblocks to get a pointer to the buffer and perform type casts rather than copies as I showed above in comment #16. The same applies to downloaded arrays, but you’ll need raw access to the array rather than using something likeMemoryStream.You mention that you’re not “sure if the CopyTo is a double hop,” so I’d recommend looking at the relevant source code you’re using such as in the Amazon or .NET libraries. Decompiling with a tool like ILSpy usually gives reasonably readable results if you only have DLLs. You should be able to find the DLLs in the
PROJECTNAME_OSNAME_BackUpThisFolder_ButDontShipItWithYourGamedirectory when you do a build of the game.#21 by Jonathan Bayer on March 26th, 2019 ·
Great article, thanks
However, I have the opposite problem:
I am writing a few bytes to a number of files, many times a second. However, the problem I’m describing also occurs when doing this loop once every two seconds:
Assume the number of files is 6 (from my test): I find that every so often, Unity will just stop and hang for a period of time between 5 and 10 seconds. I’m assuming that it’s either garbage collection or some other strange overhead. Any ideas how to stop this?
Thanks
#22 by jackson on March 26th, 2019 ·
I recommend using tools like a profiler or a debugger to find out what’s going on. Unity’s profiler is an easy place to start that will tell you most issues. If it’s lower level than that, such as deep in the engine or the OS, then attaching a C++ debugger to the Unity process and manually breaking execution during the hang will tell you what’s executing at the time. If you’re still stuck after that, I recommend trying to strip away parts of your project until you’re left with just the code that’s causing the problem. This will either highlight what the issue is so you can work around it or leave you with a sample project you can submit to Unity along with a bug report.
Good luck finding the issue!
#23 by Mark Castle on July 17th, 2019 ·
Just wanted to say great article and very useful plus amazing that you’ve answered everyone’s comments and questions in detail.
Didn’t prove to be directly relevant to what I’m looking for but just wanted to say the above nevertheless :-)
Cheers
#24 by Muhab on November 8th, 2019 ·
Hey Jackson,
It is a great honor to read your article as I have been using BinaryReader/Writer for years to parse/write bunch of data that can reach 100~ mb per second in an async modeled console application which causes my host cpu lately to overload due to the increasment of my users usage which really affected my business few months ago but now after reading this article, I am about to rewrite my data handlers using your examples to reach my desired scalability and outsize my business.
Best Regards!
#25 by Key Matthews on December 22nd, 2019 ·
Hi Jackson,
Outstanding article, Jackson. This is very good information on how you’re able to find a way to improve the stream ability to read 11 times faster with the use of the ‘BufferedBinaryReader method’.
Jackson, I have a question to ask you. First of all, and for most, I very new to the ‘Stream’ classes. Should I use the ‘BufferedBinaryReader Class’ for reading mp3 files from c# wcf services for streaming to end users for an Android app? And if so, can you show me an example of what my operation contract (Iservice) and the implementation (service) of my method would be like. I really would appreciate your help very much.
My data contract:
The TrackUrl string property file path is stored in SQL Server and the actually mp3 file is in a folder of the directory of my web server (IIS). My wcf application is currently buffering mp3 file, which is very slow to efficiently read the tracks, due to the fact I can’t seek or partially read bytes of data using buffering.
My service contract:
My Operation contract method implementation:
#26 by jackson on December 29th, 2019 ·
BufferedBinaryReaderis useful when your code reads small chunks of the file, such as the four bytes of anint, at a time. If you want to load an entire file or just one large chunk, like you might be doing with this MP3, then you can just useFileStreamor even the convenience methods inFile.#27 by aybe on June 11th, 2020 ·
When it comes to performance, RAM beats storage.
In my case I had +1000 tests running over small files for about 2 minutes.
So I tried this -> read the whole file into a MemoryStream.
Turns out it’s already 40x faster from 2 mins to 3 secs :D
After all it makes sense, when you look at all these old games written in C, they just fread the whole file and process it after.
In my case RAM usage is okay, the sum of these files don’t exceed 100Mb which by today’s standards is acceptable.
But I admit your approach is more conservative and certainly deserves to be considered since mine is just plain brute force :DDD
#28 by Mirko on April 28th, 2021 ·
Hi, I have a custom binary file for storing data about 3d objects and part of it is read like this:
is it possible to optimize this? it can be thousands reads, n > 5000
thanks!
#29 by jackson on April 30th, 2021 ·
Hi, you’ll want to read in big chunks of this data from the file system. Each of these 3D points is 6 bytes, so 5000 is only 30,000 bytes. Say you’re reading 4KB chunks, you’ll just need to do 8 reads to get all the data. That should go very quickly on any modern system regardless of disk technology.
Once you have the data, you’ll need to make structured use of it in some way that’s probably not an array of bytes. Probably the fastest approach is to read directly into a
NativeArray’s backing memory. You could useushortas the generic type parameter for raw element access or opt for a 3D vector type such as from theUnity.Mathmaticspackage. You’ll probably need to use someunsafecode to go with this approach.#30 by Sot on June 7th, 2023 ·
Hello Jackson,
thanks for the great article!
I am trying to perform something similar to your solution for the code below. But I am new to the whole thing and I am not sure how to achieve this. Could you please give me some guidance. Thanks!
#31 by Sot on June 7th, 2023 ·
#32 by jackson on June 7th, 2023 ·
Hi Sot, I’m not really sure what the problem is from this limited code snippet. If you could describe the problem in more detail and provide more context I might be able to better help.
#33 by Sot on June 8th, 2023 ·
Thanks for the quick reply Jackson.
So at initialization of the project there are several calls to get the data needed using BinaryReader.
Most of them use a similar implementation as the initialize(BinaryReader br) method I already shared.
https://drive.google.com/file/d/1rEadEjdNDJv42oUDQlkdUXLkxbvtOTci/view?usp=drive_link
is a profiler snapshot of what is happening behind the scenes.
My question is if I could use your solution to reduce loading times and how..?
Also, is there a way to reduce GC allocations cause it goes quite high.
The screenshot shows 0.6mb for this particular case but it will go up to 10+mb for all similar initialize(br) calls.
#34 by jackson on June 8th, 2023 ·
Your screenshot shows 63232 calls to
BinaryReader.ReadInt32but only 3744 calls toFileStream.RefillBuffer, meaning the buffer is refilled every ~16.9 integers or ~67.6 bytes. That’s a really tiny buffer. You might benefit from controlling the buffer manually such as by passing 4KB (as in the article) toBufferedBinaryReader. There’s only one way to know for sure: try it in your project on your target hardware and measure with the profiler.As for the GC, that’s a whole separate topic and one that I’ve covered extensively in the GC tag.
#35 by Yves on January 14th, 2025 ·
Thanks for the interesting article. It makes sense to reduce the number of times some data is pushed to somewhere. But does it actually still apply to .NET 9? I see many optimisations have been applied up to there and the BinaryReader seems to be simpler now (when looking at the source that I get when following the definition in Visual Studio).
I’m creating a specialised database libary that stores time series of number values. Each record is from 2 to 9 bytes only (fixed size), including a flags byte, in one variant with an additional time value. I’m using BinaryReader and BinaryWriter for the access to different number types, and a normal FileStream for file access. I’ve already implemented my own CachedStream that I could put between my database and the FileStream to apply page caching of different sizes and counts. But it didn’t improve anything and even made some scenarios slower (2x). Also, some of my unit tests are still failing with the cache. Visual Studio profiling can’t tell me where the time went, other than it’s 99% kernel time.
So now I’m considering implementing my own ReadInt16(), WriteInt16() and all the others. It wouldn’t be hard to do that. And for double values, there should be converters like in the Buffer class or from BinaryPrimitives (used by BinaryReader). But since my own page cache didn’t help, and I can’t see all the if statements you’ve shown above, I’m wondering if it’s worth the effort. Also, FileStream is said to have some buffering already included for a while. But I can’t verify that because FileStream is very convoluted on the inside, with abstract strategies and other obfuscations.
#36 by Yves on January 16th, 2025 ·
So, I did that now. First I got rid of the BinaryReader and BinaryWriter and copied most of their implementation (just very few lines per method) into my class. That allowed me to get rid of the Stream interface and access a byte array cache directly. Until now, no performance gain.
Next was applying a single-page buffer/cache for the 4096-byte page I’m currently on. Whenever something should be read, I took it from the current buffer and continued in the next page if needed. That gave me a small performance gain. Unfortunately I can’t remember the numbers anymore as I was also playing with many variants at the same time. But it was something around 0% for Debug and 20% for Release.
In my particular case, when writing to the file, the file header is also updated. So writes go to the data location as well as the first page. So next I took the multi-page cache logic from my CachedStream (that didn’t have any performance gain at all) and brought it in. Now I have 16 pages of 4096 bytes each. Whenever something should be read, the corresponding page is looked up from the cache and data is read from there. If a page is missing, it’s loaded, and maybe another least-recently-used page is unloaded (writing if dirty, discarding otherwise). But the first page is not unloaded. (Actually, when writing to it regularly, it should stay alive anyway, now as I think of it.) This has brought a total performance gain of 0% in Debug (at least it’s not noticeably negative) and 50% in Release.
That’s all I could get. Not bad, but not as much as hoped for either.
My take-away is: Stream is slow. Don’t use the Stream interface if you can avoid it. Prefer direct byte array access if that’s where the data lives. Span and stackalloc byte[] can help avoid temporary allocations (I haven’t measured it though).
The records in my file can be stored in sorted order, and when that’s the case, I can find them with binary search instead of a full scan. That cranked the Release-build gain of my long unit test up to 95% in total. Much bigger effect than the cache.
#37 by Chris on January 17th, 2025 ·
This is just a problem with .NET and its insane paranoid implementation in general. Why people keep insisting to write performance code with a framework that is obviously not capable of it is beyond me.
Why anyone would want to make a game with it is just as baffling.